Data Transformation ToolsMedallion Architecture
Key Concepts
Multi-chapter guide | Chapter 5
Medallion architecture is a strategy that organizes data in a lake house, incorporating multiple layers to improve data quality, analytics, and management. It typically works as a three-tiered data structure:
Bronze layer—unformatted raw data
Silver layer—transformed and cleaned data
Gold layer—data ready for business use and analytics.
Such an architecture promotes data traceability, governance, and modularity when introducing new data sources. Medallion architecture is most effective for large data sets due to its organizational advantage and systematic management ability. The architecture is typically implemented using data lake/warehouse technologies such as Hadoop, Hive, and Spark. It is also widely used on modern SQL-based platforms such as Snowflake and Databricks.
While medallion architecture can be an effective way to manage data, it comes with its challenges. Developers need to spend significant time developing an optimal design and implementing the framework from scratch while maintaining accuracy in transformations and avoiding data leaks. Also, the silver layer becomes complex over time because most key transformations lie within it.
This article reviews the key concepts of medallion architecture and its implementation.
Summary of key medallion architecture concepts
| Concept | Description |
|---|---|
| Three-tiered design | Separation of data into layers depending on their readiness for business use. |
| Data ingestion | Efficient ingestion of data from external sources into the bronze layer. |
| Data transformation | Accurate transformation and enhancement of raw data into silver and gold layers. |
| Data usage and analytics | Data access and usage in each of the three layers. |
| Data governance | Maintaining data integrity, security, and ownership across all layers. |
| Scalability & performance | All three layers are ready to adapt to growing needs and expanding data volumes. |
#1 Three-tiered design in medallion architecture
Any system that implements medallion architecture is centered around a three-tiered design. Each layer has a specific purpose in terms of storage and transformations. This separation promotes scalability and maintainability and allows engineers to work independently on various layers.
Bronze layer
The bronze layer’s primary role is to collect raw data from multiple external sources. It either stores data as a direct copy or acts as a staging layer where data is marginally parsed and transformed into a standard format like Snowflake or Parquet. The bronze layer usually holds large data volumes, part of which might not be immediately essential but potentially valuable for data analysis in the future.
Below is an example of what raw data of a user’s login history might look like when stored in the bronze layer.

2024-10-01T10:00:00Z, INFO, User login successful, user_id=12345
2024-10-01T10:00:05Z, INFO, User login successful, user_id=23456
2024-10-01T10:00:10Z, ERROR, Failed to load resource, resource_id=67890
2024-10-01T10:00:15Z, INFO, User logout, user_id=12345
2024-10-01T10:00:15Z, INFO, User logout, user_id=12345
2024-10-01T10:00:20Z, WARN, High memory usage detected, usage=85%
2024-10-01T10:00:25Z, INFO, User login successful, user_id=34567
2024-10-01T10:00:30Z, INFO, User profile update, user_id=23456
2024-10-01T10:00:30Z, INFO, User profile update, user_id=23456
2024-10-01T10:00:35Z, ERROR, Database connection failed, attempt_id=98765
2024-10-01T10:00:40Z, INFO, User logout, user_id=23456
2024-10-01T10:00:45Z, WARN, High CPU usage detected, usage=90%
Silver layer
The silver layer uses data from the bronze layer to implement the most crucial transformations of the architecture and is usually the most processing-intensive section. Cleaning, ordering, and data quality are the primary goals of this layer. Normalizing and enrichment are also commonly done. The silver layer usually implements a schema that organizes the raw data from the bronze layer. Using the previous example, the following is what the user data might look like once formatted in the silver layer.
| Timestamp | Date | User ID | Action | Status | Resource ID | Error Message | Usage |
|---|---|---|---|---|---|---|---|
| 2024-10-01T10:00:00Z | 2024-10-01 | 12345 | login | success | N/A | N/A | N/A |
| 2024-10-01T10:00:05Z | 2024-10-01 | 23456 | login | success | N/A | N/A | N/A |
| 2024-10-01T10:00:10Z | 2024-10-01 | N/A | resource_load | error | 67890 | Failed to load resource | N/A |
| 2024-10-01T10:00:15Z | 2024-10-01 | 12345 | logout | success | N/A | N/A | N/A |
| 2024-10-01T10:00:20Z | 2024-10-01 | N/A | high_memory_usage | warning | N/A | N/A | 85 |
| 2024-10-01T10:00:25Z | 2024-10-01 | 34567 | login | success | N/A | N/A | N/A |
| 2024-10-01T10:00:30Z | 2024-10-01 | 23456 | profile_update | success | N/A | N/A | N/A |
| 2024-10-01T10:00:35Z | 2024-10-01 | N/A | database_connection | error | N/A | Database connection failed | N/A |
| 2024-10-01T10:00:40Z | 2024-10-01 | 23456 | logout | success | N/A | N/A | N/A |
| 2024-10-01T10:00:45Z | 2024-10-01 | N/A | high_cpu_usage | warning | N/A | N/A | 90 |
Gold layer
The gold layer contains aggregated and refined data ready for business use. As the enterprise-wide functioning model, it serves various business units within the organization according to their requirements. For example, a company can directly derive reports and analytics that help improve business performance and revenue.
The gold layer is, therefore, more oriented toward user-friendliness, performance, and accuracy. Valid gold layer data for the previous user-login example could look like this.
| Date | User ID | Total Logins | Total Logouts | Total Errors | Avg Memory Usage | Avg CPU Usage | Last Login |
|---|---|---|---|---|---|---|---|
| 2024-10-01 | 12345 | 2 | 1 | 0 | 85 | 0 | 2024-10-01T10:00:00Z |
| 2024-10-01 | 23456 | 2 | 1 | 1 | N/A | 0 | 2024-10-01T10:00:05Z |
| 2024-10-01 | 34567 | 1 | 0 | 0 | N/A | 0 | 2024-10-01T10:00:25Z |
| 2024-10-01 | N/A | 0 | 0 | 2 | N/A | N/A | N/A |
Optional platinum layer
Occasionally, organizations may include a platinum layer in their medallion architecture. The platinum layer is responsible for further and advanced data analysis of the gold layer. This could involve predictive and forecasting modeling required by specific business units. For example, a platinum layer for a subscription-based organization could analyze the patterns of customers ending their memberships or becoming dissatisfied and produce related forecasting reports. Having said that, the platinum layer is an emerging concept and is only sometimes involved in the typical architecture.

Medallion architecture (Source)
#2 Data ingestion
Data ingestion is the method by which data is absorbed into the bronze layer. Steps include:
Identify and accept data sources like databases, APIs, and raw files.
Collect raw data from the selected source without any content changes.
Clean and format data depending on the engineer’s requirements.
For example, the Python script below would work with Spark as a data processing engine to collect data from an API, convert it to a Snowflake format, and store it with minimal change in the bronze layer.
from pyspark.sql import SparkSession
import requests
# Initialize Spark session
spark = SparkSession.builder \
.appName("Bronze Layer Data Ingestion") \
.getOrCreate()
# Step 1: Collect data from an API
url = "https://api.example.com/data"
response = requests.get(url)
data = response.json()
# Step 2: Create a DataFrame from the API response
df = spark.createDataFrame(data)
formatted_df = df.select(
"product_id",
"name",
"category",
"quantity",
"price",
"sale_date",
"region_id"
)
snowflake_options = {
"sfURL": "example.snowflakecomputing.com",
"sfDatabase": "exampleDatabase",
"sfSchema": "exampleSchema",
"sfWarehouse": "exampleWarehouse",
"sfRole": "role",
"sfUser": "user",
"sfPassword": "password"
}
# Write DataFrame to Snowflake
formatted_df.write \
.format("net.snowflake.spark.snowflake") \
.options(**snowflake_options) \
.option("dbtable", "bronze.products") \
.mode("overwrite") \
.save()
# Stop Spark session
spark.stop()
An organization normally makes its bronze layer versatile and complex by accepting more sources and implementing further data checks to remove unwanted data. Planning for the bronze layer must be meticulous to provide scalability and future accessibility. The architect has to plan the following:
Data sources that may become important in the future.
Whether any data can be omitted entirely.
Performance optimizations due to high data ingestion volumes.
It can be quite tricky for engineers and architects to create completely scalable medallion architecture for their data from scratch, as it requires a lot of foresight. If not planned carefully, bronze layer ingestion mechanics can become complicated and hard to manage. Many data sources that eventually relate through foreign and composite keys in a database table add to the architecture’s complexity.
#3 Data transformation
While data transformation technically occurs in all medallion architecture stages, it is most prevalent in the silver layer.
Silver layer
The silver layer is typically responsible for
Removing duplicates and populating missing values
Structuring the data into columns, tables, and schemas
Converting raw data into data types (e.g., string to date)
Consolidating individual batches of data ingested into the bronze layer into a single dataset
The below example displays the logic used to convert the data from the previous data ingestion example into silver layer quality data.
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
spark = SparkSession.builder \
.appName("Silver Layer Data Transformation") \
.getOrCreate()
# Snowflake configuration
snowflake_options = {
"sfURL": "example.snowflakecomputing.com",
"sfDatabase": "exampleDatabase",
"sfSchema": "exampleSchema",
"sfWarehouse": "exampleWarehouse",
"sfRole": "role",
"sfUser": "user",
"sfPassword": "password"
}
bronze_df = spark.read \
.format("net.snowflake.spark.snowflake") \
.options(**snowflake_options) \
.option("dbtable", "bronze.schema") \
.load()
# Remove duplicates
cleaned_df = bronze_df.dropDuplicates()
# Populate missing values
populated_df = cleaned_df.fillna({
"name": "Unknown",
"category": "Miscellaneous",
"quantity": 0,
"price": 0.0,
"sale_date": "1970-01-01", # Default date
"region_id": "Unknown"
})
# Convert raw data into appropriate data types
converted_df = populated_df \
.withColumn("sale_date", F.to_date(F.col("sale_date"), "yyyy-MM-dd")) \
.withColumn("quantity", F.col("quantity").cast("integer"))
# Load additional data for joining (product details)
product_df = spark.read.format("delta").load("data/productData")
# Join data into columns
final_df = converted_df.join(product_df, "product_id", "left")
# Write DataFrame to Snowflake
final_df.write \
.format("net.snowflake.spark.snowflake") \
.options(**snowflake_options) \
.option("dbtable", "silver.schema") \
.mode("overwrite") \
.save()
# Stop Spark session
spark.stop()
The code uses Spark and Python to extract data from the initially developed bronze layer and refine it further. It removes duplicates, populates missing values, and converts data into standardized data types (e.g., string to date for sale_date column).
The silver layer is the least clearly defined layer in medallion architecture. Frequently, it tends to be a catch-all bucket for transformations and data structures that don’t fit into either Bronze or Gold layers. This ambiguity often leads to overwhelming complexity of the data and transformations contained in the Silver layer, making this a significant challenge when developing an efficient medallion architecture for a data lake. For instance, the above code is highly simplified and shows signs of becoming verbose, considering only a few transformations are implemented. A large organization with various data and business requirements would have far lengthier and more complicated logic in its silver layer. This can result in data transformations that are hard to manage and scale on an enterprise level.
A complicated silver layer often leads to performance degradation and confusion within evolving teams. An inefficient silver layer could also domino effect the gold layer, impacting data quality and performance.
Gold layer
While the silver layer is responsible for the most integral transformations, the gold layer involves transformations from a business perspective. It typically involves aggregating and modeling all silver layer data for business-centric visualization.
The below example continues the previous example code.
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
# Initialize Spark session
spark = SparkSession.builder \
.appName("Gold Layer Data Transformation") \
.getOrCreate()
# Snowflake configuration
snowflake_options = {
"sfURL": "example.snowflakecomputing.com",
"sfDatabase": "exampleDatabase",
"sfSchema": "exampleSchema",
"sfWarehouse": "exampleWarehouse",
"sfRole": "role",
"sfUser": "user",
"sfPassword": "password"
}
# Load data from the Silver Layer
silver_df = spark.read \
.format("net.snowflake.spark.snowflake") \
.options(**snowflake_options) \
.option("dbtable", "silver.schema") \
.load()
# Aggregate data for reporting
aggregated_df = silver_df.groupBy("category") \
.agg(
F.sum("quantity").alias("total_quantity"),
F.sum("price").alias("total_revenue"),
F.avg("price").alias("average_price")
)
# Enrich data with external sources (market trends)
market_trends_df = spark.read.format("csv").option("header", "true").load("data/marketTrends")
enriched_df = aggregated_df.join(market_trends_df, "category", "left")
# Create a final reporting view
final_report_df = enriched_df.select(
"category",
"total_quantity",
"total_revenue",
"average_price",
"market_trend"
)
# Write to a reporting database or dashboard
final_report_df.write \
.format("net.snowflake.spark.snowflake") \
.options(**snowflake_options) \
.option("dbtable", "gold.schema") \
.mode("overwrite") \
.save()
# Stop Spark session
spark.stop()
This script creates a final report using the previous silver layer data containing business-level columns such as revenue and market trends. Again, in the basic example, you can see signs of a complex silver layer introducing verbosity to the required reporting in the gold layer. There is also potential for performance issues when extracting data from the silver layer.
#4 Data usage and analytics
Data usage
While the medallion architecture’s ultimate goal is to provide meaningful and clean data for various business purposes, transformed and untransformed data in each of the three layers also provides valuable information. In a medallion system, it’s common for data to be accessed and queried throughout its lifecycle, not just at the endpoint. For example:
Analysts typically pull data from the bronze layer in their original formats (CSV files, JSON logs, etc.) to assess ingested data quality and use these results to examine the validity of data sources.
Data scientists use machine learning algorithms on the silver layer to train data.
Business users base their data dashboards on silver layer data for deeper analysis of a data pipeline.
Data scientists and engineers use gold layer data for higher-level predictive modeling with enriched data.
Augmented analytics
Data usage in a medallion architecture is more commonly coupled with augmented analytics to enhance data handling. Augmented analytics can be used in any layer and support data ingestion, cleansing, and transformation. You also gain insights without needing to conduct manual deep dive analyses. Examples of augmented analytics in medallion architecture include:
Ingestion automation in the bronze layer, including source adaptation and converting to initial data formats.
Trend automation and pattern detection within the silver layer using cleaned and expansive data.
Gold layer and historical data analytics to provide business users with strategic recommendations.
Augmented analytics typically benefit data-intensive companies, such as e-commerce or financial ones. They support business strategies heavily affected by trends, predictions, and historical analytics.
#5 Data governance
One of the most beneficial outcomes of implementing a medallion-style architecture in your data warehouses is its traceability. Since data follows a streamlined path of bronze, silver, and gold, you can document it in every state and time. Such a practice helps with auditing and promotes data quality. Engineers and users are accountable for data modification, validation, and security.
Metadata recording within all layers should be present to record every transformation process and external source interaction. Apache Atlas is a recommended metadata management tool commonly used with Spark.
You should also implement role-based access control (RBAC) to the entire system to limit data access. This can be done by creating a role and permission system within the data lake.
Data governance checks for each layer
Bronze layer
Schema validation tools like JSON Schema or Apache Avro ensure that source data is compatible with the system’s predefined schema requirements.
Data source verification ensures that data is being ingested only from an approved source.
Silver layer
Double-check dependencies between columns and foreign key relationships for consistency.
Calculate statistical flags like Z-score, median, and IQR to detect data anomalies implying quality issues.
Data quality checks include handling null values, data types, etc.
Gold layer
Business rule validation ensures that resultant data is consistent with data formats requested by business stakeholders.
Aggregation and calculation formulas should be constant across the project.
#6 Scalability and performance
Scalability and performance optimization should be prioritized when developing medallion architectures due to the extensive data handling involved. The inherent modularity of each layer means performance is usually far better than if the entire dataset was worked on monolithically. However, there is always room for further improvement within each layer.
While there are many methods to improve performance and scaling abilities, there are several points an architect has to keep in mind to ensure scalability is covered on all grounds for now and in the future. Designing medallion architecture is time-consuming and complex.
Data formats
Choose optimized data formats in your bronze layer (Parquet or Snowflake) to promote quicker read and write operations from data ingestion.
Data processing frameworks
Frameworks like Spark perform dynamic resource allocation and reduce the burden on engineers to develop optimal solutions. For example, Spark allows us to auto-scale executors based on job demand within a data pipeline. Spark also gives us the ability to cache intermediate results for future use.
Cloud-based storage
Cloud-based data lakes like AWS S3 offer elastic storage capabilities that make both horizontal and vertical scaling simple and cost-effective.
DataForge and medallion architecture
DataForge provides pre-built medallion architecture on its Databricks lakehouse platform. Organizations can integrate fully functioning medallion strategies into their data lakes without spending hours developing optimal solutions and designs for each data layer. Besides reducing the burden on engineers to develop entire architectures, DataForge has integrated data governance features such as standardized storage layers, naming conventions, data retention policies and others, all easily managed via user-friendly UI controls.
More technically, DataForge’s pre-built architecture has significant performance and modular impact on the silver layer of the medallion format. A change data capture (CDC) process flags incoming records as new, changed, or unchanged. It significantly improves performance as it avoids data reprocessing in the silver layer. Such a mechanism also improves data traceability.
DataForge also automatically standardizes and governs the silver layer. This limits multiple complicated transformations while providing the flexibility to customize incoming data.
The DataForge architecture also provides a platinum layer in addition to the three standard layers. This platinum layer provides customized outputs for individual business units, easily defined in the UI if necessary.
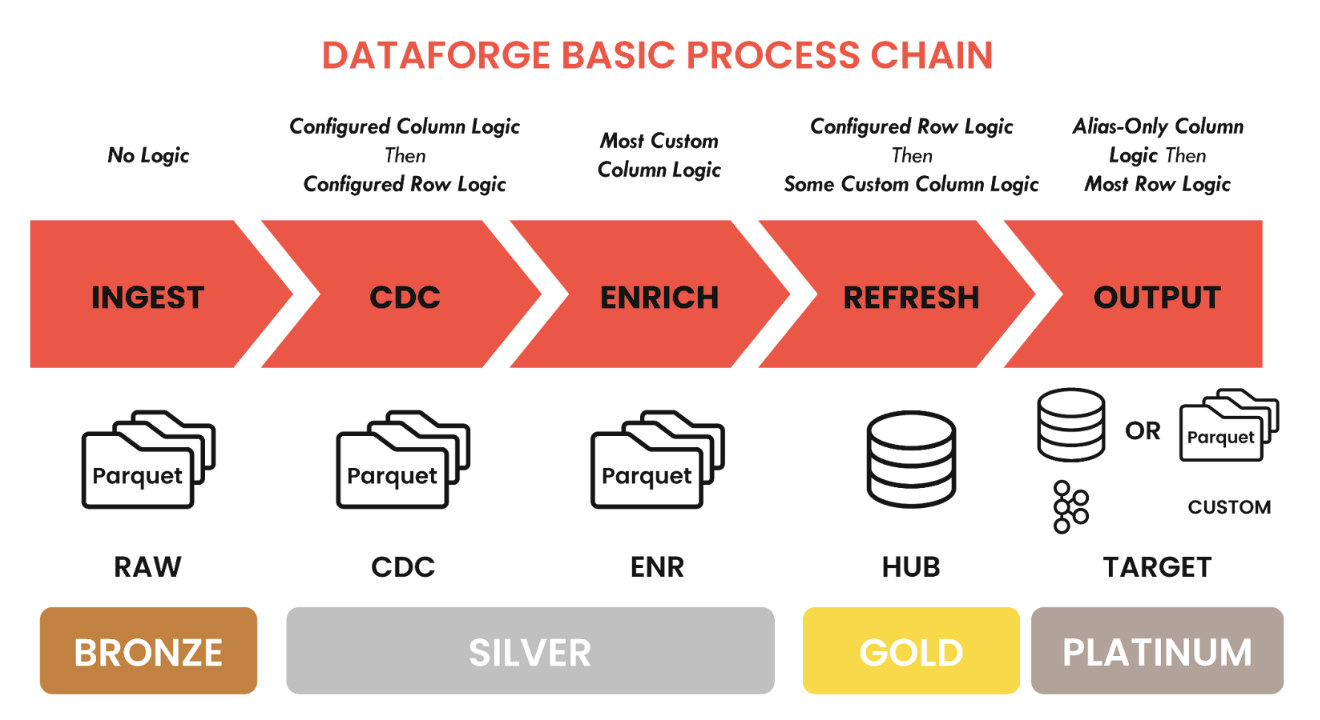
DataForge in-built medallion storage-based process chain
Conclusion
The medallion architecture can be a helpful strategy for organizations to manage large data volumes effectively. It improves an organization’s ability to implement data governance and transformations and enhances performance within the data lake. In addition, the layered approach of the architecture allows for smooth collaboration between teams working on different project parts. However, one needs to develop a scalable solution early on to avoid growing complexities in the silver layer.