Data Transformation ToolsThe Must-Have Features of Modern Data Transformation Tools
Multi-chapter guide | Chapter 1
Business runs on data; however, raw data in its original form holds limited value. Data transformation involves converting data from one format or structure to another suitable for analysis, aggregation, and reporting.
Manual data transformation involves hand-coding scripts to clean and reformat data. It requires data processing engines and writing code using their low-level APIs. While this approach offers flexibility and control, it is highly time-consuming and prone to human error.
Modern businesses generate and transform large data volumes using complex logic, which requires serious processing power. Manual methods fall short in today’s data environment due to their inefficiency, even though they allow customized transformations. As data pipelines grow, maintaining and debugging code becomes increasingly tricky.
Data transformation tools significantly reduce the time required for transformations, minimize human error, and ensure high data quality. They provide an abstraction over the data processing engines and facilitate faster development of data transformation. They are essential for data engineers, as they enforce best practices, automate repetitive tasks, and ensure data integrity.
This article explores some of the better-known tools available for data engineers and highlights the must-have features modern data transformation tools should possess. These features streamline the data transformation process and enhance the efficiency and reliability of data workflows.
Summary of the must-have features of data transformation tools
| Desired feature | Description |
|---|---|
| Declarative transformation | Specifies what transformation should be done, not how to do it. |
| Dependency management | Automatically handles dependencies between data transformations. |
| Orchestration integration | Orchestration tools help define operating schedules and workflows using modular transformation jobs. |
| Modularity | Break down transformations into reusable, modular components. |
| Version control | Tracks change in transformation scripts, CI/CD integration and enable audits. |
| Metadata management | Manages and maintains metadata to ensure the context and meaning of data transformations. |
| Data lineage | Traces the data flow and transformations to ensure transparency and traceability. |
| Ease of operation | Data transformation tools must enable easy initial load, unload, reload, and backfill data. |
| Logging and error handling | Logging the key events and raising errors with clear messages is key to debugging any issues in data transformation. |
| Popular data transformation tools | An overview of the popular data transformation tools, such as Spark SQL, PySpark, Apache Hop, DBT, and DataForge. |
Before discussing these features, let’s examine where data transformation tools fit into the data engineering pipeline.
Understanding data transformation tools
Transforming large amounts of data according to complex business logic requires highly optimized runtime environments that operate on high-end servers or distributed clusters and expose their APIs for implementing business logic. These runtime environments can be:
Separate specialized systems focusing only on execution OR
Databases that provide storage and analytical querying capability using an SQL layer.
Apache Spark and its variations, like Databricks, are the de facto enterprise data processing execution runtimes these days. Spark provides high-level APIs for languages like Python and Scala and has a strong SQL layer called SparkSQL. Similarly, massively parallel processing databases like AWS Redshift, BigQuery, Apache Kylin, etc., represent data warehouses with strong querying layers.
Writing transformation logic using low-level programming APIs of the processing frameworks or SQL layer of the databases is a complex task. Hand-coding complex logic using these APIs or SQL often results in code that is hard to debug and maintain. Once pipelines become connected and complex, keeping track of the data lineage and controlling the deployed versions becomes difficult.
This is where data transformation tools come into the picture. They provide an abstraction over the processing frameworks and SQL layer to make it easy for developers to write clean, modular, side-effect-free, maintainable code.
Next, let's examine the typical features one must focus on when selecting a data transformation tool.
#1 Declarative transformation
Declarative transformations describe what the computation must perform without enforcing control flow. This contrasts with imperative programming, which uses a sequence of statements to describe how the program must accomplish its tasks.
Imperative programming in data transformation results in modules that often impact non-local variables other than their output (side effects). Such modules can not be reused because of the uncertainty of their impact on the whole system if run outside their designed logical flow. It results in unhealthy patterns like ‘run only once’ or ‘exactly twice.’

Typical transformation pipeline with side effects that can not be modularized.
For example, in SQL, a SELECT statement is considered declarative because it does not change the state of any non-local variable. However, an ordered sequence of DML statements like INSERT, UPDATE, etc., are considered imperative since developers specify the order of the statements and may rely internally on side effects produced by previous statements. The ideal solution is a programming framework implementing all kinds of transformation logic as declarative functions.
If you are new to applying functional programming to SQL, read this article to learn more about the concepts that enable declarative transformation.
#2 Orchestration integration
Data orchestration is the process of automating transformation workflows by scheduling tasks across the data pipeline. Orchestration tools like Apache Airflow and Dagster manage various data processing tasks, ensuring they are executed in the correct sequence and according to defined dependencies.
Integrating declarative transformations with orchestration tools is essential for further enhancing the efficiency and scalability of data transformation processes. Declarative transformations focus on the "what" (the logic of data transformation), while orchestration tools handle the "how" (the execution flow and dependencies). This separation ensures that each component does what it is best at.
However, with DataForge, orchestration is not required. Unlike other tools that separate the "what" from the "how" into distinct transformation and orchestration layers, DataForge, available in open-source and hosted versions, provides a fully declarative approach that handles not only the logic of data transformation but also the order of execution, all within a unified framework simplifying the workflow and eliminating the need for separate orchestration tools.
#3 Dependency management
Organizations with large data volumes and aggregated reports often have a complex network of transformation tasks that must run in a predefined sequence. Within such networks, transformation tasks are defined with dependencies and triggers.
Dependencies — other tasks(modules or jobs) that must run before the transformation task to set up the appropriate inputs for transformation.
Triggers—downstream tasks that start once the transformation task is completed successfully.
The data transformation tool should automatically handle dependencies and triggers to reduce manual tracking and the potential for errors. This way, issues related to incorrect execution orders can be prevented, and the reliability of data pipelines can be improved.
Here’s a checklist to ensure your data transformation process is efficient and reliable.
Document all transformation jobs and their dependencies.
Specify triggers for each job to automate the initiation of downstream tasks.
Set up monitoring and logging for all transformation jobs.
Assign priority levels to dependencies based on their criticality.
Implement version control for transformation scripts and configurations.
Simulate various dependency scenarios to test the robustness of the job scheduling.
#4 Modularity
Modularity, or breaking down complex transformations into smaller components, has two advantages. First, it enables reusing these components in other complex jobs. Second, it makes the code more maintainable since anyone who needs to modify a small component can have a partial picture of the complex transformation. It also helps debug and test since they can be isolated to individual components.
An ideal data transformation tool enables developers to create modular code. Traditionally, the smallest unit of modularity regarding data transformation tools has been the table. Most data transformation tools enable developers to build reusable components scoped to individual tables. In most cases, tables are too big to separate from complex transformational logic, limiting the reusability of independent components. However, newer tools like DataForge allow developers to reduce the modularity scope to the cell, row, or column level.

Immutable side effect free modular transformation pipeline
To understand modularity, look at the codes below, which compare similar rules applied using SQL, Python, and modular code. Each method produces the same final transformed dataset but offers different flexibility, maintainability, and modularity advantages. SQL is straightforward for database operations, Python provides programmatic control, and DataForge offers modularity and reusability.
SQL code example

CREATE TABLE transformed_sales AS
SELECT
l_orderkey,
l_quantity,
l_extendedprice,
l_discount,
o_orderdate as order_orderdate,
o_clerk as order order_clerk,
(l_extendedprice * l_quantity) AS total_sales,
(l_extendedprice * l_quantity) - (l_discount * l_quantity) AS net_sales
FROM
tpch.lineitem
JOIN
tpch.orders ON tpch.lineitem.l_orderkey = tpch.orders.o_orderkey;
transformed_orders.sql:
CREATE TABLE transformed_orders AS
SELECT
o_orderdate,
o_orderkey,
o_clerk
FROM
tpch.orders
PySpark code example
lineItemDF = spark.read.table("samples.tpch.lineitem")
ordersDF = spark.read.table("samples.tpch.orders")
lineItemOrdersDF = lineItemDF \
.join(ordersDF, \
lineItemDF.l_orderkey == ordersDF.o_orderkey)
lineItemOrdersTransformedDF = lineItemOrdersDF \
.selectExpr("l_orderkey", \
"l_quantity", \
"l_extendedprice", \
"l_discount", \
"o_orderdate", \
"o_clerk", \
"(l_extendedprice * l_quantity) AS total_sales", \
"(l_extendedprice * l_quantity) - (l_discount * l_quantity) AS net_sales")
ordersTransformedDF = ordersDF\
.selectExpr("o_orderdate", \
"o_oderkey", \
"o_clerk")
lineItemOrdersTransformedDF.write.mode("overwrite") \
.saveAsTable("transformed_sales")
ordersTransformedDF.write.mode("overwrite") \
.saveAsTable("transformed_orders")
Modular code example
The code below is created with Dataforge, which defines source and target tables, columns, and transformation rules in a YAML file.
source_name: tpch_lineitem
source_query: tpch.lineitem
target_table_name: transformed_sales
raw_attributes:
- l_orderkey int
- l_quantity int
- l_extendedprice decimal
- l_discount decimal
rules:
- name: total_sales
expression: "[This].l_extendedprice * [This].l_quantity"
- name: net_sales
expression: "[This].total_sales - ([This].l_discount * [This].l_quantity)"
- name: order_orderdate
expression: "[tpch_orders].o_orderdate
- name: order_clerk
expression: "[tpch_orders].o_clerk
tpch_orders.yaml
source_name: tpch_orders
source_query: tpch.orders
target_table_name: transformed_orders
raw_attributes:
- o_orderkey int
- o_orderdate date
- o_clerk string
relations.yaml
relations:
- name: "[tpch.lineitem]-orderkey-[tpch.orders]"
expression: "[This].l_orderkey = [Related].o_orderkey"
#5 Version control
Transformation logic in an organization evolves based on new requirements and optimizations. As the complexity of transformations implemented using low-level APIs or SQL increases, keeping track of code changes is difficult. Production deployment also requires rolling back the code if an issue is found.
Many organizations embed significant business logic within their database code through stored procedures, triggers, and complex SQL scripts. Managing this logic without version control brings several challenges.
When changes are made to transformation logic without version control, tracking who made what change and why becomes nearly impossible.
Since changes occur frequently, it may not be efficient to keep a partial save on the tool; it should be traceable.
Without version control, reverting to a previous state in case of errors involves manually undoing changes, which can be time-consuming and prone to mistakes.
Data transformation tools must provide built-in version control, audit, and rollback features. They should be able to track changes to transformation scripts and maintain a detailed history for auditing and review.
#6 Metadata management
Metadata is information about the data assets in your repository. Knowing the identity of data assets in your repository is critical to using them effectively to derive insights. With thousands of data pipelines created over a long period, it becomes challenging for engineers to understand the reason and meaning of data sets.
Ideally, you should integrate metadata management into the development process to consistently follow the rules and keep the repository organized.
Your data transformation tool must have built-in mechanisms to keep track of metadata and its changes. It must also expose a method for engineers to access them with sufficient checks and balances. Role-based access control of metadata is as important as the access control of the data itself. Tools must also provide ways to audit the metadata and make changes based on approvals by data stewards.
Annotate the dataset with details such as
Data source: sales system
Creation date: 2024-06-12
Owner: Data engineering team
Purpose: Customer segmentation analysis
#7 Data lineage
Data lineage involves tracing data flow through various transformations right from the origin of the asset through all the changes it undergoes to reach its current state. Data often passes through various systems and transformations (hops) before reaching its final state.
A detailed trace of the data’s journey helps teams to:
Quickly pinpoint where issues originated for root cause analysis (RCA).
See precisely where the data might have been altered incorrectly or where discrepancies were introduced.
Understand the dependencies between different data sets and transformations.
Data lineage is essential for understanding the impact of changes on data and applications. One method to generate data lineage is to evaluate the metadata without dealing with code transformations. However, there are better methods.
The ideal solution is for the transformation tool to keep track of logic and tag the input and output of all tasks that go through it. Tracking data lineage and generating a visual map is a must-have feature in the data transformation tool. It must also keep track of all the errors that occur during transformation and log them with appropriate messages for further debugging.
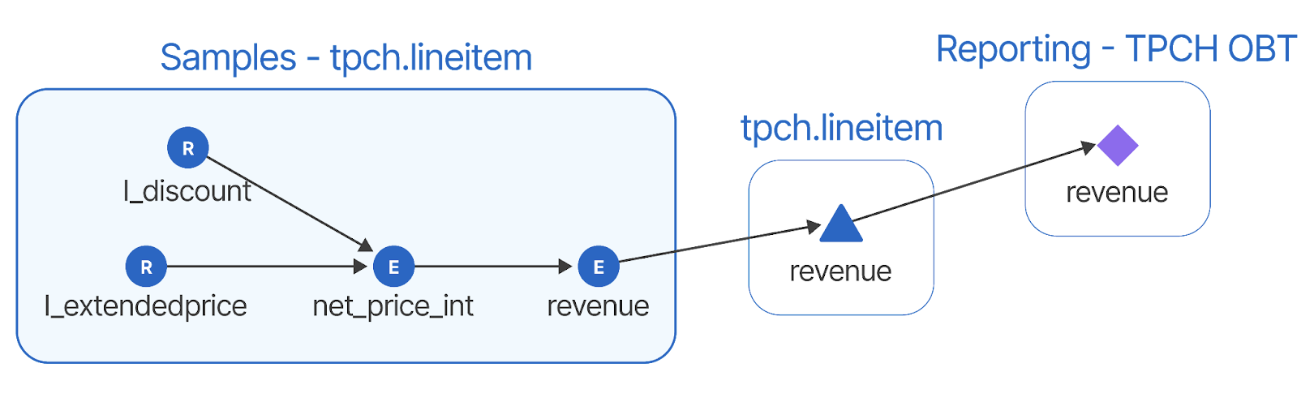
Data lineage example
However, many tools can only track lineage at the table level, while modern tools like DataForge can track lineage at the field level, greatly enhancing troubleshooting.
#8 Ease Of Operation
A data transformation tool must be easy to operate to be accepted in an organization. This means easy data loading, unloading, and reloading in data engineering projects if necessary.
Simple APIs for accomplishing these initial setup tasks help improve developer productivity and reduce the time to production. Ideal data transformation tools provide user interfaces and comprehensive connector support for all the popular data sources to reduce this initial setup time.
#9 Logging And Error Handling
The ideal data transformation tool must have a comprehensive trail of logs to enable debugging when something goes wrong. The logs must capture and retain all such events for a decent amount of time to aid investigation. It must also have support for log rotation so that the deployed server does not run out of resources.
Another key aspect of transformation tools is how they react to errors and handle them gracefully without affecting other jobs. Several events can cause a job to fail in the data engineering landscape. There could be connectivity issues with the source or destination, the schema may differ from what the job expects, or the transformation logic may take more time or resources than expected. The transformation tool must be able to identify all such scenarios and log them to aid further investigations and reruns.
Popular data transformation tools
Now that we understand the must-have features of a data transformation tool let's explore some options.
Spark SQL provides a SQL execution engine over Spark's low-level APIs. This helps developers focus on the implementation's business logic rather than dealing with the complexities of Spark APIs. Spark’s immutation style of table scoping helps bring some modularity into the implementation, but it does not have a UI or features for lineage tracking, audit, metadata management, etc.
PySpark combines the speed of Apache Spark with the ease of Python and has an interface similar to Spark SQL. It allows you to handle big data with the same ease as you work with smaller datasets in Python. With PySpark, you can process massive amounts of data quickly while still letting you write code in a language you're comfortable with without getting bogged down by the complexities of big data tools.
Apache Hop is an open-source data integration platform that enables visual programming to accelerate the development of transformation logic. Hop provides a GUI and a native engine that can run transformation jobs. It also supports Apache Spark, Flink, or even cloud-based data processing engines like Google Dataflow as the processing run time.
DBT is a SQL-first data transformation tool that offers modularity, portability, and lineage tracking that is lacking in typical SQL-based transformation implementations. It helps developers combine Python-based logic with SQL to express logic declaratively, resulting in simpler pipeline architectures. DBT’s core framework is open source, but the DBT cloud, which includes the Cloud IDE, is proprietary.
DataForge is a next-generation data transformation tool that leverages functional programming principles to provide a robust and scalable solution for data transformation needs. It breaks down transformations into reusable, modular components and efficiently handles large datasets through parallel and distributed processing. DataForge is available in open-source (a.k.a., DataForge Core) and hosted (a.k.a., DataForge Cloud) versions. It is known for its highly modular transformation logic that can operate at the cell, column, or row level.
Conclusion
Data transformation tools provide an abstraction over data processing frameworks and SQL engines to help developers build data pipelines adhering to standard software engineering practices. They allow developers to write side-effect-free, modular code that is easy to maintain and debug. Such tools have built-in features for version control, audits, and data lineage tracking.