May 7, 2024
Introducing DataForge Core: The First Functional Code Framework for Data Engineering
How DataForge Core brings agility and efficiency to data engineering.
Have you ever contemplated the distinction between Software Engineering and Data Engineering? Although both deal with data in some capacity, their methodologies are fundamentally different.
Software engineers harness a combination of computer science principles and libraries to facilitate and uphold best practices such as DRY, SRP, and OCP. These tools empower developers to craft, sustain, and scale dependable and extensible codebases.
Conversely, in modern Data Engineering, SQL scripting reigns supreme as the go-to method for data transformations. Originally conceived in the 1970s alongside relational databases, SQL streamlines both schema (DDL) and data management (DML) within databases, making it an indispensable tool for those purposes.
However, employing SQL within data engineering pipelines can yield negative repercussions:
- Recurring copy-paste patterns (e.g., change data capture, refresh, audit, data quality)
- As SQL scripts are table-scoped, they can expand into lengthy documents, obfuscating lineage and necessitating substantial effort to debug, maintain, and evolve
- SQL joins may inadvertently result in data loss or duplication, posing formidable challenges for debugging
- Any alteration to the output schema of any single SQL script mandates schema changes and the “backfilling” of all intermediate tables, as well as updates to all downstream SQL scripts
These issues precipitate an exponential trend in the complexity of data engineering pipelines with growth, often resulting in what is colloquially known as “spaghetti code.” This proliferation of complexity directly translates into out-of-control costs associated with building, maintaining, supporting, and evolving an enterprise data platform.
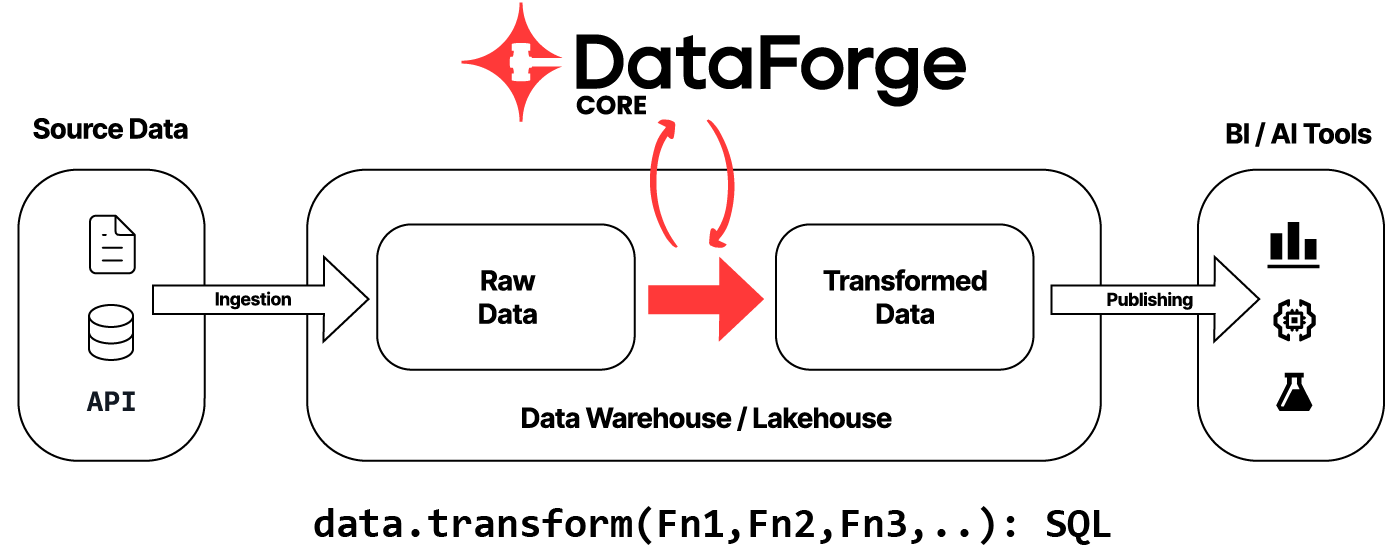
I am thrilled to announce that DataForge has open-sourced its data transformation framework: DataForge Core. This framework enforces modern software engineering best practices and allows data engineers to delineate transformations at the most granular, columnar level. Each transformation is articulated as a pure, single-column-valued function expressed in SQL columnar syntax, with implicit arguments.
The DataForge framework operates on the principle of inversion of control, compiling columnar transformations specified by developers, validating syntax, determining data types, and generating executable SQL scripts that facilitate transformations in the correct order based on dependencies. Additionally, the framework generates DDL SQL CREATE and ALTER statements for both the final output and all intermediate tables.
Discover more about DataForge Core on Github, and please share your feedback with us!
Ready to try DataForge?
Start with the Community plan — free forever — or talk to our team.