June 10, 2024
DataForge Unveils Version 8.0: Transforming Data Management
DataForge Release Version 8.0, continuing its mission to make data management faster and easier.

DataForge continues its mission to make data management, integration, and analysis faster and easier than ever
DataForge, the Declarative Data Management platform, has released its latest version, enhancing ease of use and adding new connectivity options for Databricks customers. With these updates, DataForge continues its mission to empower enterprises to build, grow, and expand data products.
Introducing DataForge Cloud 8.0! Packed with powerful new features and enhancements, this version is designed to elevate your data management capabilities. Here’s a glimpse of what’s new:
- Handle Complex Data Types with Ease: DataForge Cloud 8.0 now supports array and struct data types commonly found in semi-structured datasets like JSON, API results, and streaming data. Leverage these complex types seamlessly in rules, relations, templates, output mappings, and filters. The intuitive expression editor helps you navigate nested types effortlessly, ensuring a smoother data processing experience.
- Integrate Event Data with Kafka: DataForge Cloud 8.0 introduces Kafka integration for Sparky Ingestion and Output, enabling batch reads and writes from any Kafka topic. Support for Avro and JSON schemas, along with Schema Registry connections, ensures seamless event data integration into your workspace.
- Introducing Talos AI Assistant: Meet Talos, DataForge’s new virtual assistant. Talos can help you find connections, list and search schemas and tables, create sources, and much more. Available in preview for DataForge Cloud Professional and Enterprise customers on AWS, Talos is here to enhance your data management experience.
For more details, please see the release notes below or visit www.dataforgelabs.com.
Table of Contents
- Handle Complex Data Types with ease
- Extended Schema Evolution
- Integrate Event Data using Kafka into your workspace
- Streamlined Import/Export format 2.1
- Project management puts more control in your hands
- Easily duplicate Workspace level configurations
- Enhanced Processing details user experience
- Benefit from upgraded Databricks Runtime
- Google Cloud Platform (GCP) support
- Talos AI Assistant
Handle Complex Data Types with ease
DataForge added support forarray andstruct data types. These types are common in semi-structured datasets (JSON), API results, and streaming.
You can now use these complex types along with scalar types in rules, relations, templates, output mappings, and filters. The expression editor intelli-sense will help you navigate nested complex types by listing child keys for each nested level. Structs and Arrays display a metadata icon with further schema definitions. You can also use all available spark built-in functions in rules.
In output mappings, you have the option to expand mapped struct attributes. This will create new columns named as
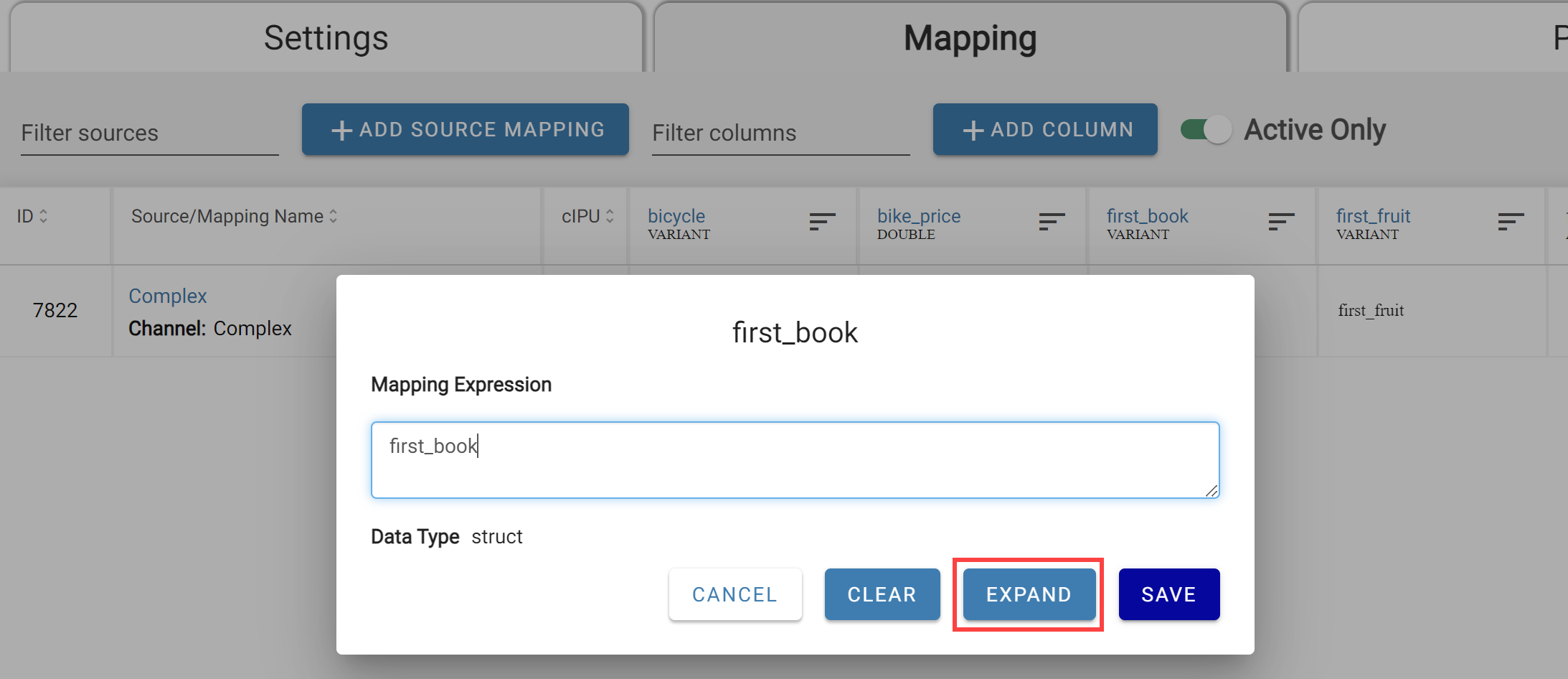

You can also do this for all structs in the channel by clicking Expand Structs in the channel options menu.
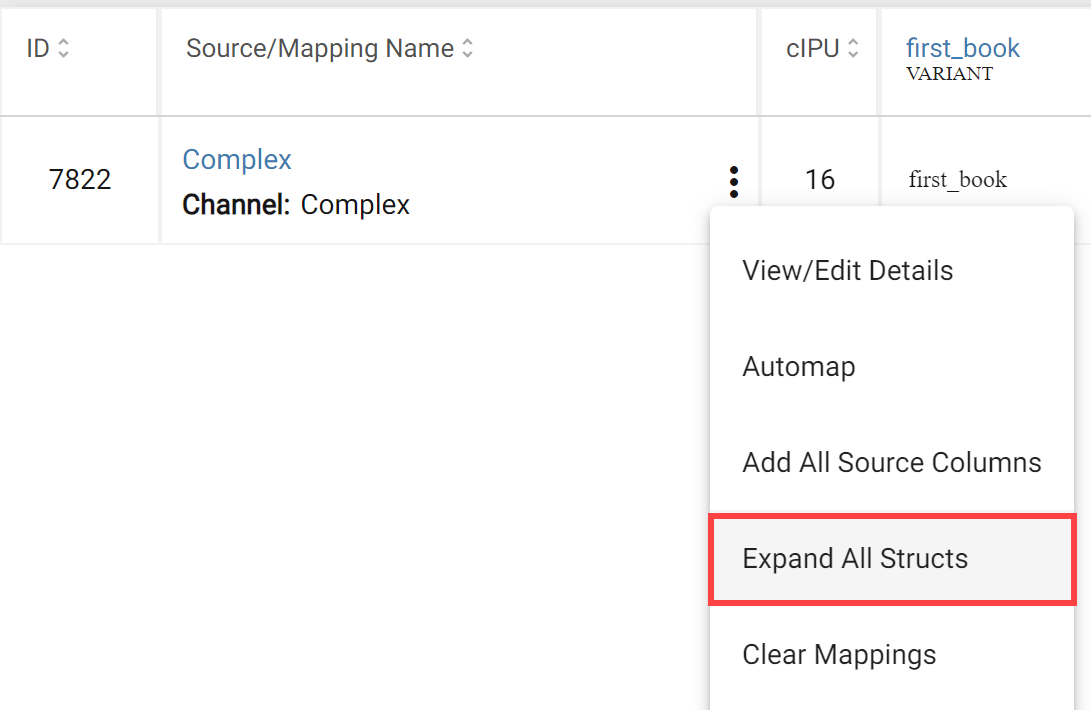
Clicking this option recursively will expand nested structs to the next level.

DataForge recommends using Databricks’ higher-order functions for working with complex nested arrays. In a future release, DataForge plans to introduce a new sub-source feature to fully integrate nested arrays of struct operations into the platform at the columnar level, further streamlining the experience of working with complex types.
Extended Schema Evolution
A new “Schema Evolution” parameter extends DataForge capabilities with the following settings:
The Schema Evolution parameter is in the source parameters Parsing section. It contains a drop-down with 7 preselected combinations of the above settings. The default setting is Add, Remove, Upcast.
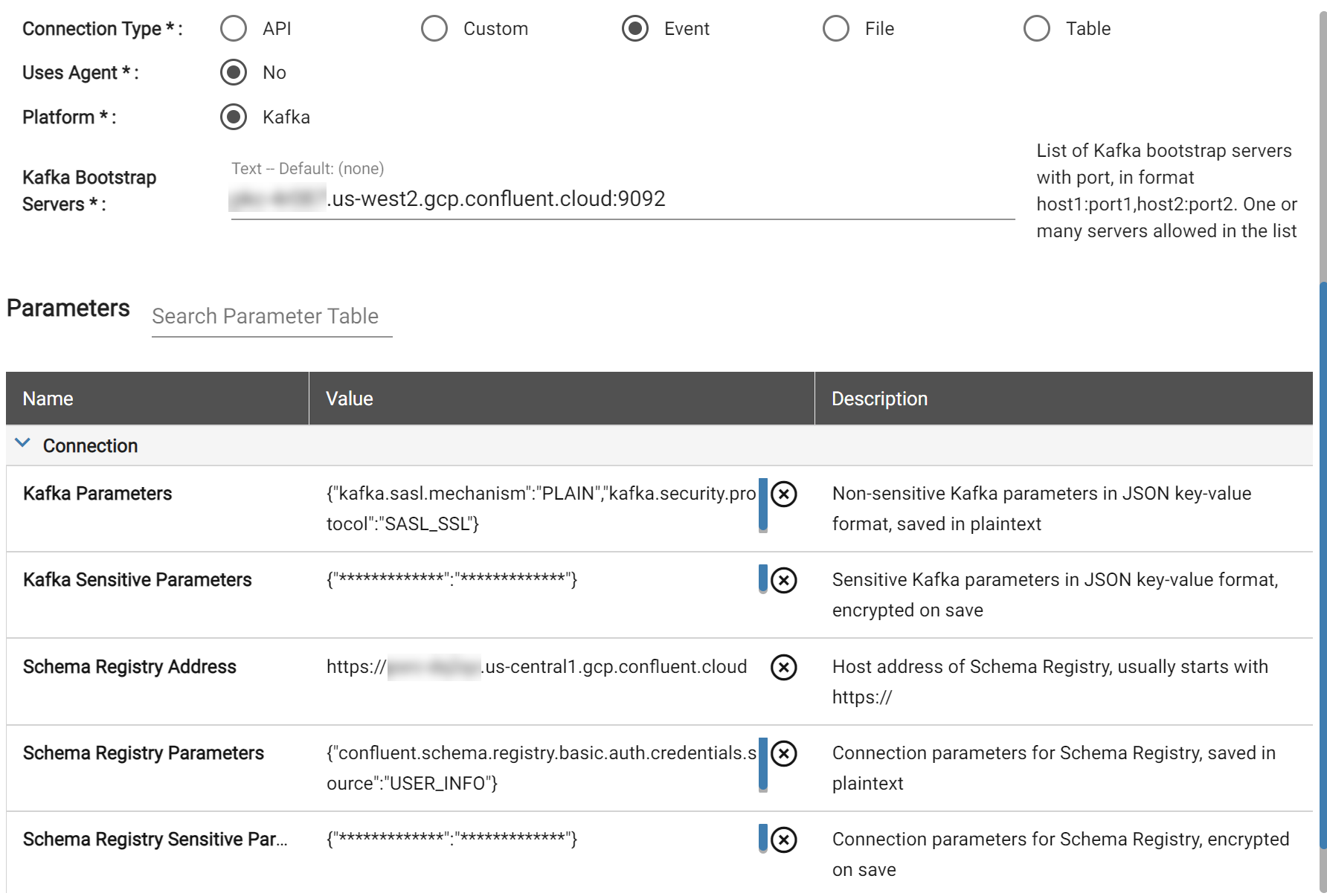
Integrate Event Data using Kafka into your workspace
Event integration using Kafka is now supported for Sparky Ingestion (Databricks cluster-based) and Output, to do batch writes and reads from any Kafka topic. Avro and JSON schemas and Schema Registry connection are supported using parameters defined in the Connection.
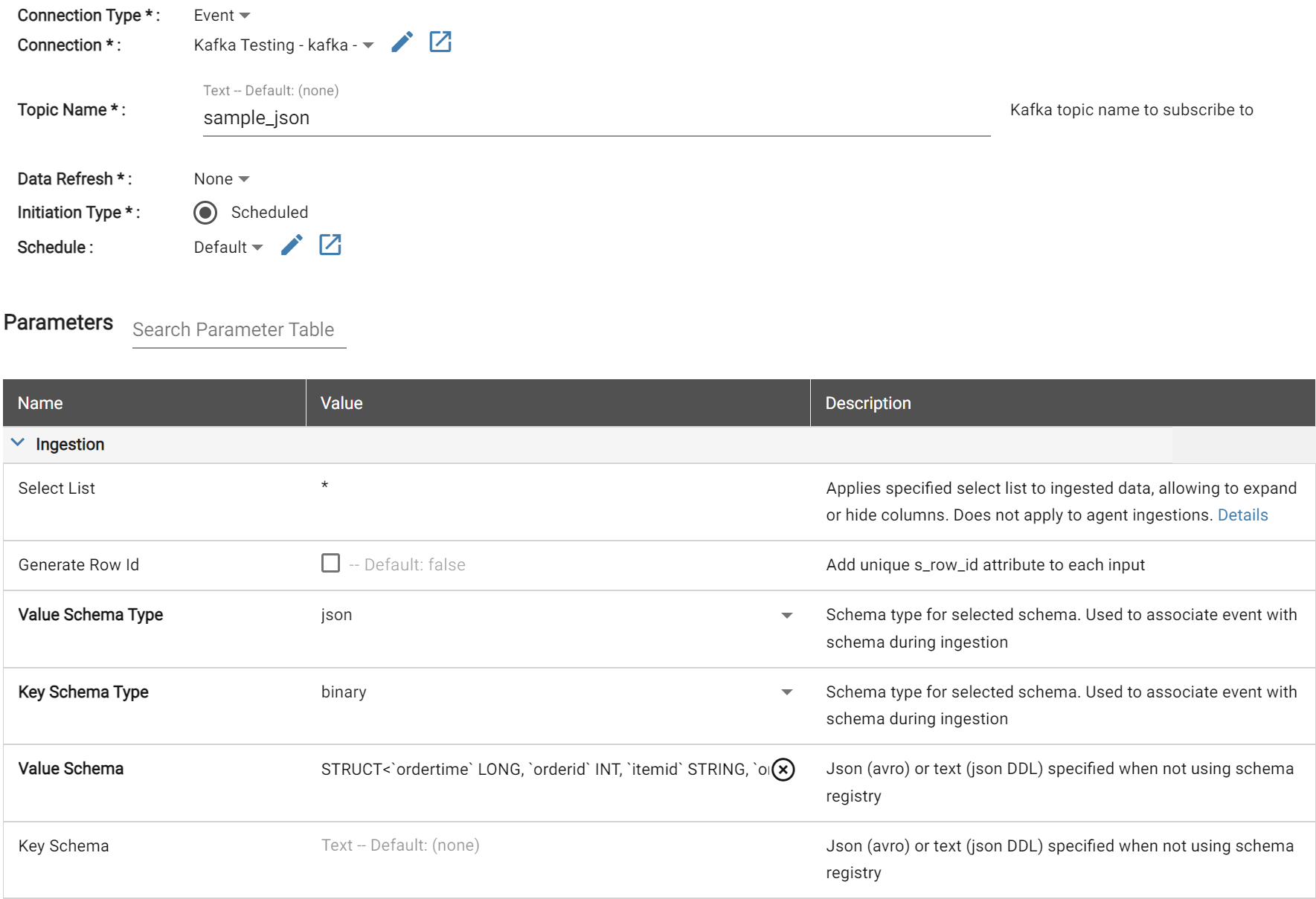
Currently, only batch reads and writes are supported, with full streaming integration coming in a future release. Starting and ending offsets are supported on Ingestion, with the ability to set the starting offsets to “deltas” to ensure each ingestion is always pulling the latest batch from the Kafka topic. Additional parameters exist within the Source ingestion parameters for further refining the data flow.
For output, key/value columns are supported, and users set up the value column in a rule if it’s necessary to make a complex type in the value.
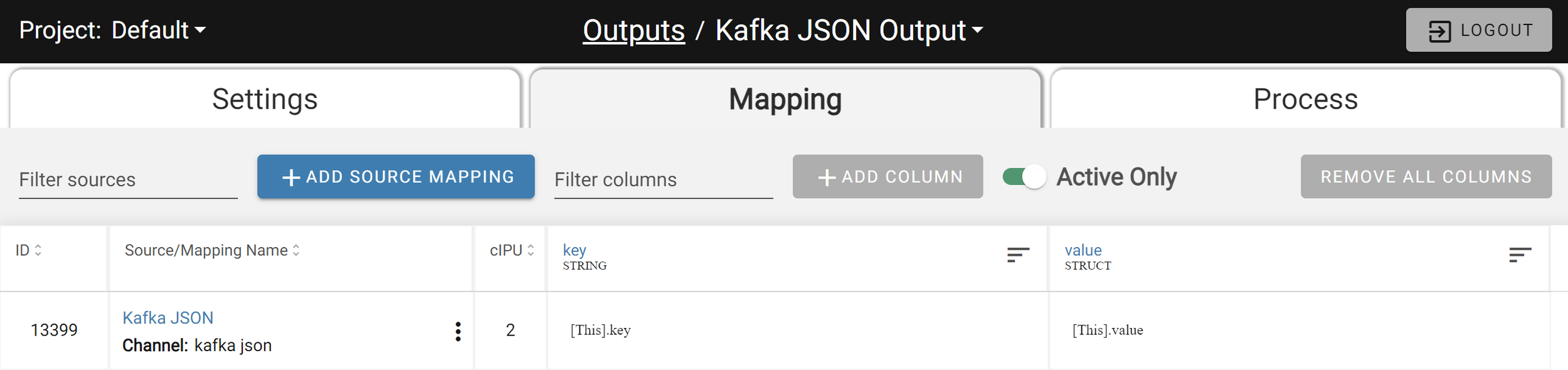
Streamlined Import/Export format 2.1
New export format 2.1 removes all attributes containing default values from YAML files. This results in a significant 2-3x reduction in the size of export YAML files and less code to manage and source control.
Additionally, relations have been moved to a single standalone relations.yaml file in the root folder of the import zip. The relations format has been simplified as in this example:

Centralized relation files make it easier to maintain and avoid duplication.
Format version is defined in the meta.yaml file in the root folder of the import zip.
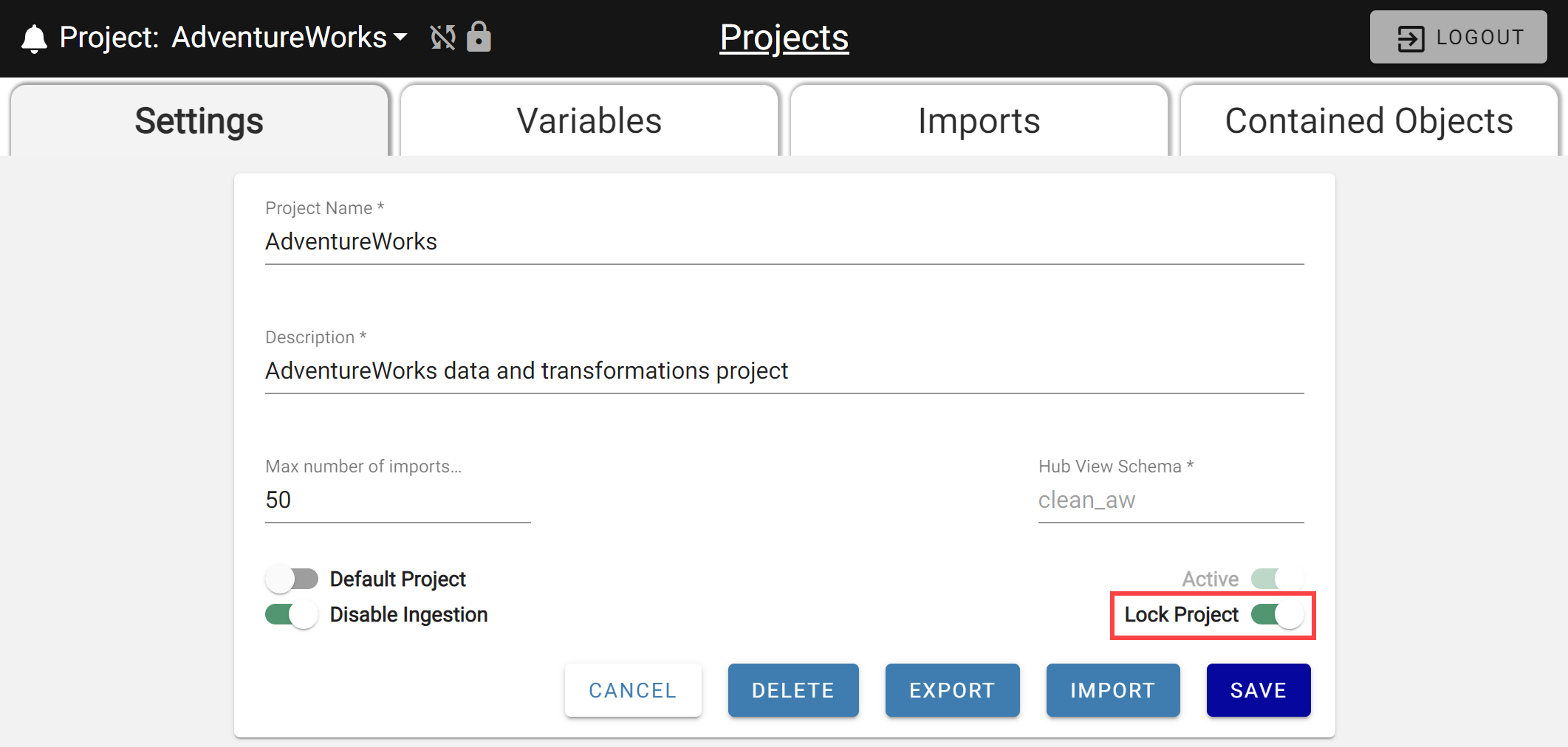
**Project Management puts more control in your hands **
Ensure Projects that are live in production are never accidentally modified by using the new Lock Project option. Easily enable or disable the project lock by updating the flag on the project settings and saving the change.
When a project is locked, only changes made via project import are allowed. Trying to edit any configurations or settings in the project manually while it is locked is prevented.

Locked projects are indicated on any page of the Workspace by the lock icon presented to the right of the project name drop-down.
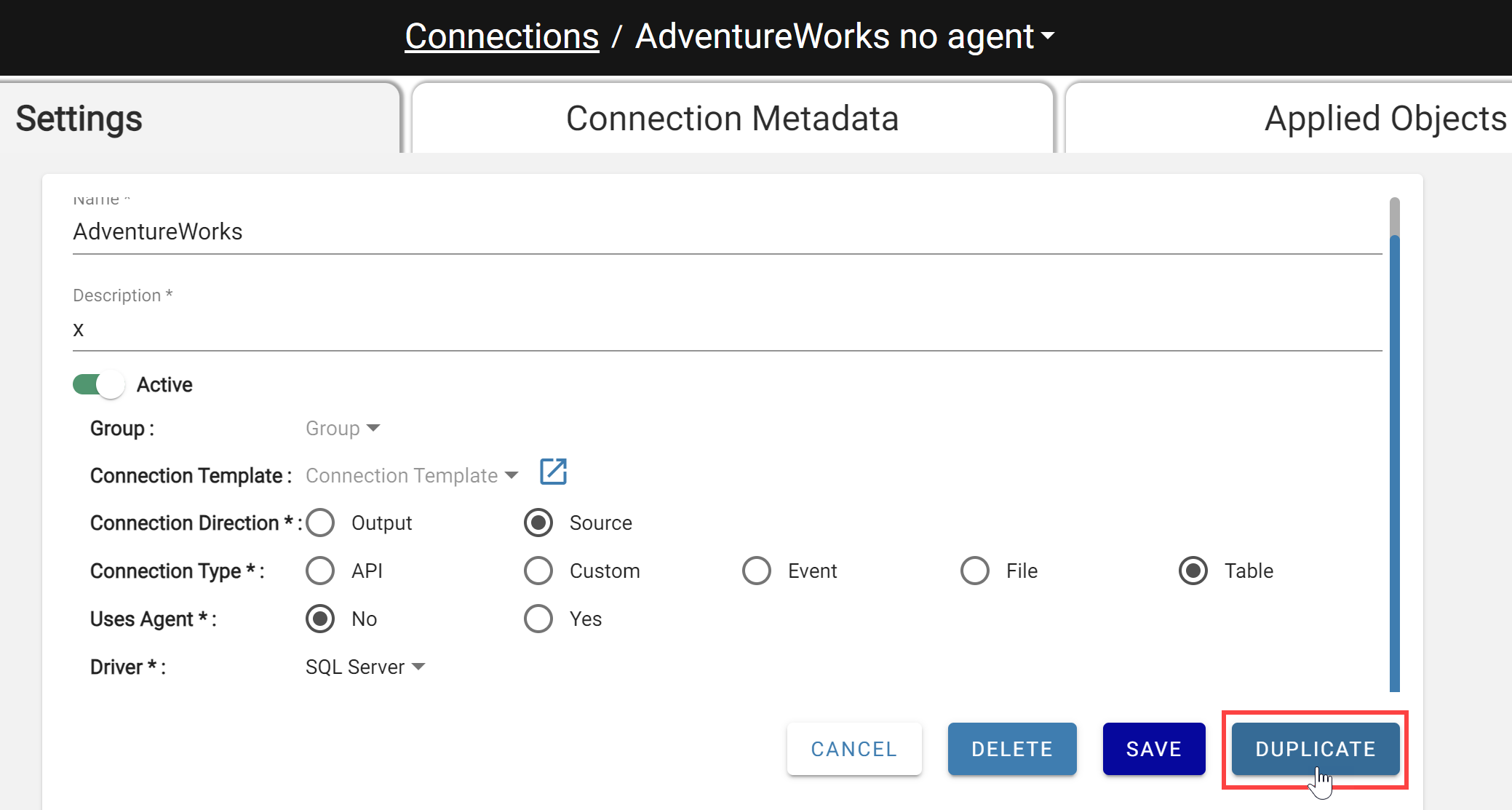
**Easily duplicate Workspace level configurations **
Easily duplicate workspace-level configurations within the Workspace, including Process Configurations, Cluster Configurations, and Connections.
Use the Duplicate button on any configuration and DataForge Cloud will launch a new tab with the same settings and a name of ”
Enhanced Processing details user experience
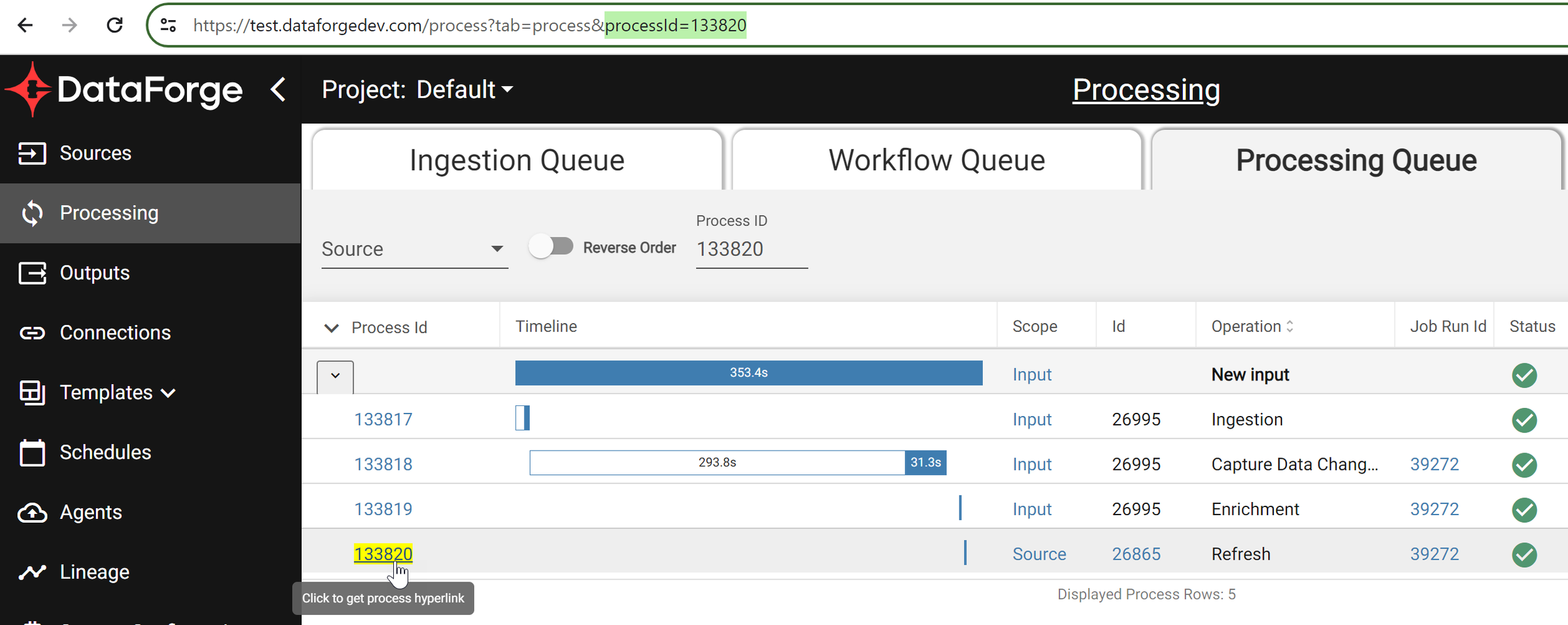
DataForge Cloud now supports copying and sending direct hyperlinks to specific processes. Share process-specific links for direct context with others while troubleshooting.
Click the Process ID hyperlink to highlight the process ID and copy the new URL from the browser window. Alternatively, right-click the Process ID hyperlink and copy the link address. Available on all Processing screens (main, source, output).
Easily filter many processes at a time to narrow down your search results by filtering on start and end hours. The start and end times are based on your browser’s local time setting. Change the hours and hit the Enter key, or click the Refresh button to adjust your view easily. Available on all Processing screens (main, source, output).
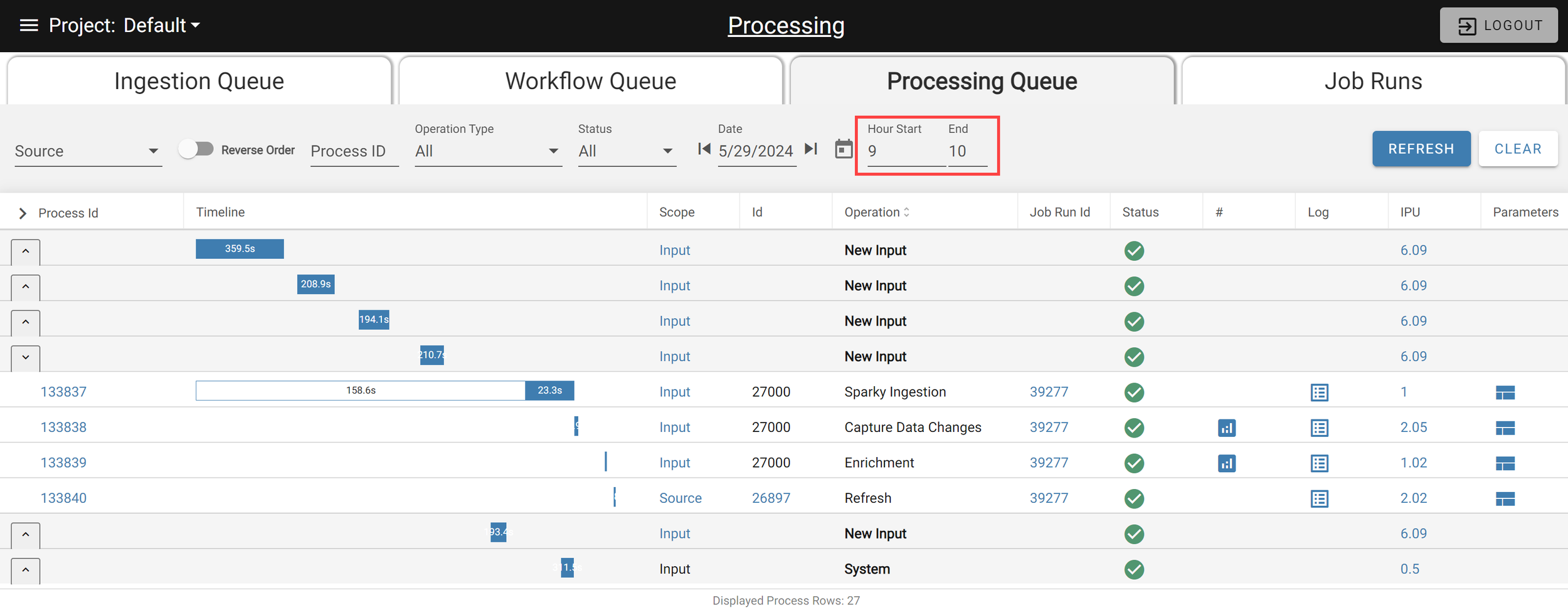
Search for a specific process by entering the Process ID in the Process ID filter to narrow it down to a specific process. This feature is available on all Processing pages.
Benefit from upgraded Databricks Runtime
The default Databricks version for cluster configurations has been updated to DBR 14.3 LTS. For more information, visitDatabricks 14.3 LTS documentation.
Google Cloud Platform (GCP) Support
DataForge Cloud now offers support for Google Cloud. In addition to AWS and Azure, DataForge Cloud seamlessly integrates with Google’s powerful cloud services and resources.
Talos AI Assistant
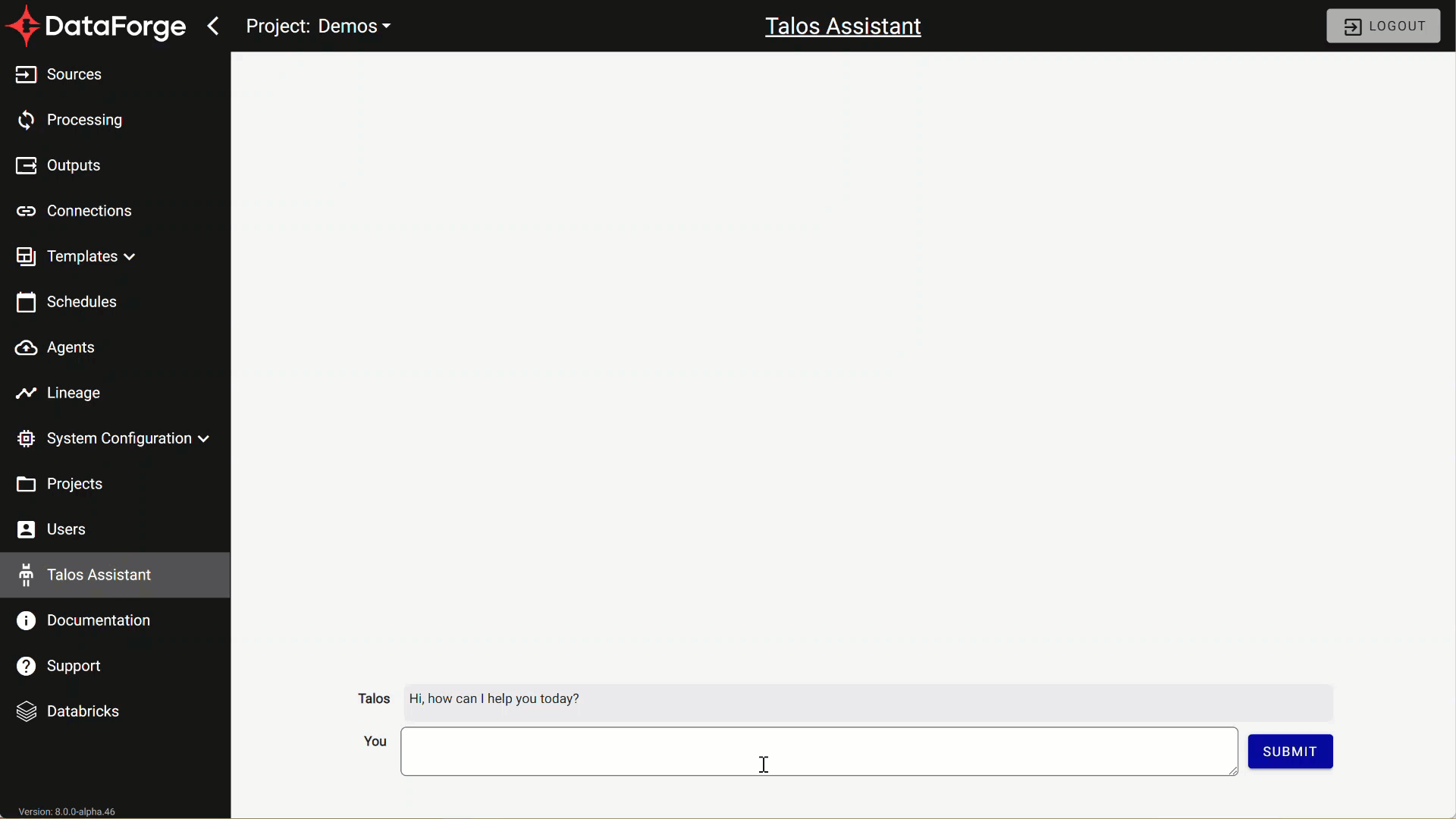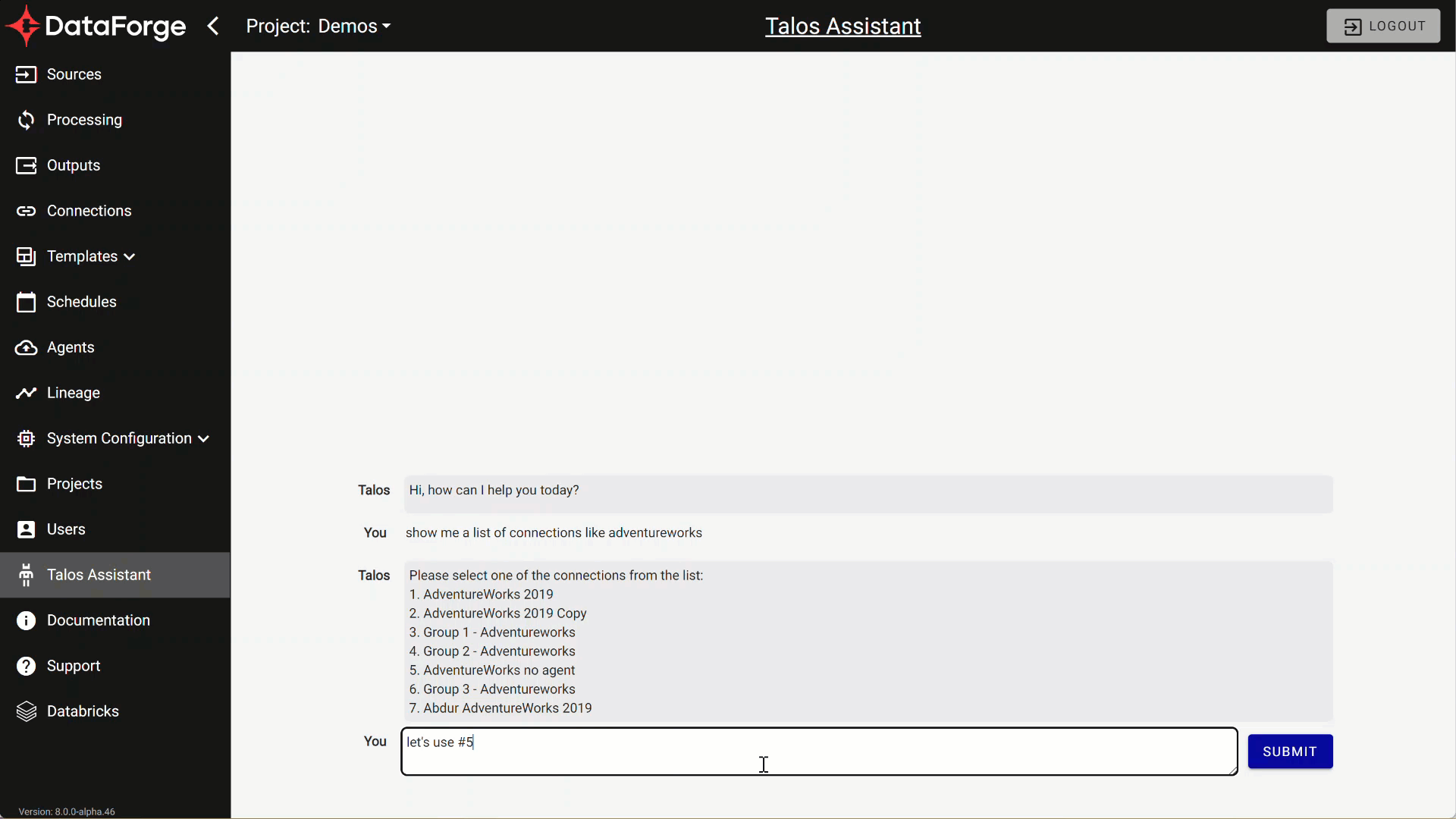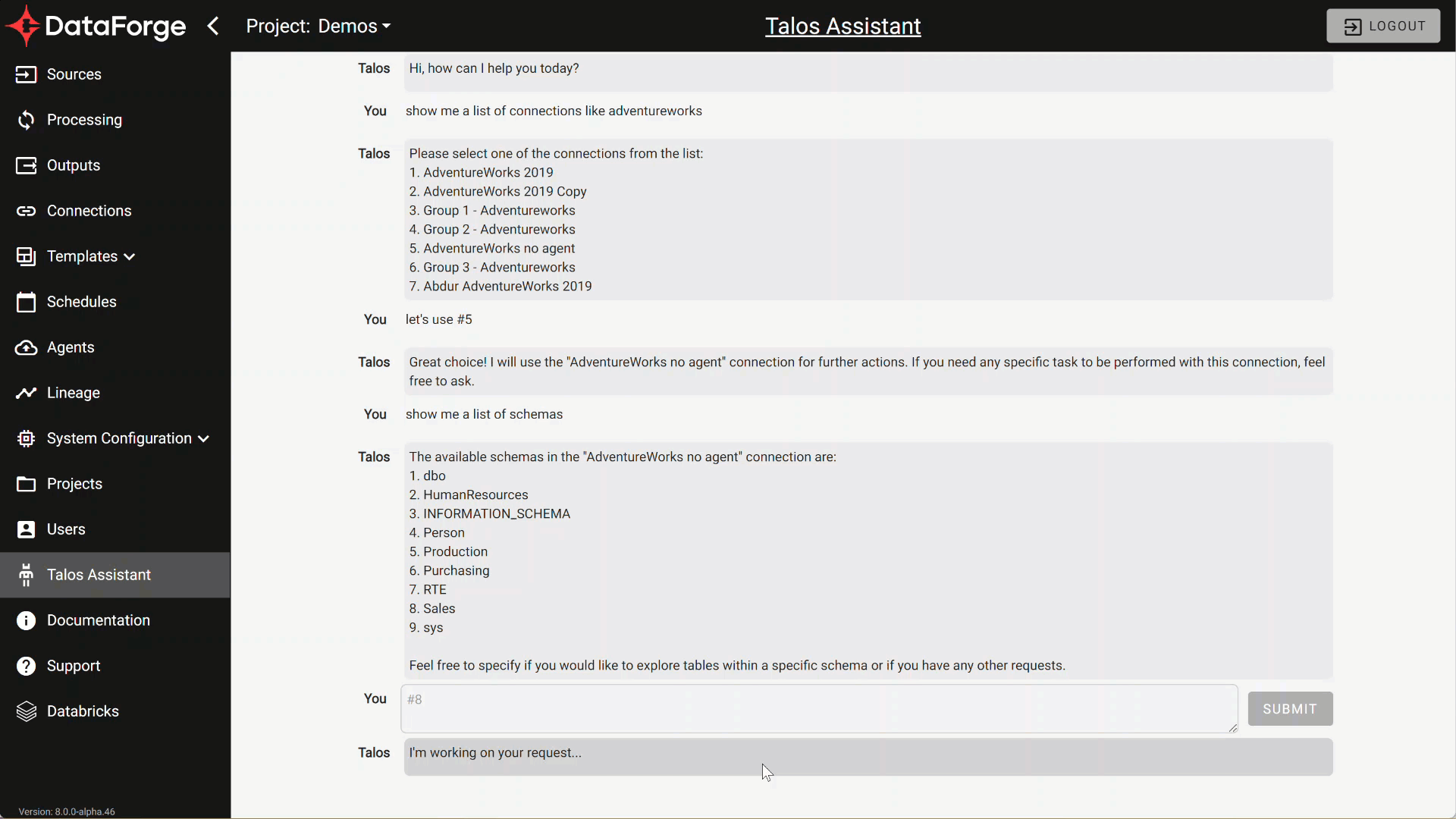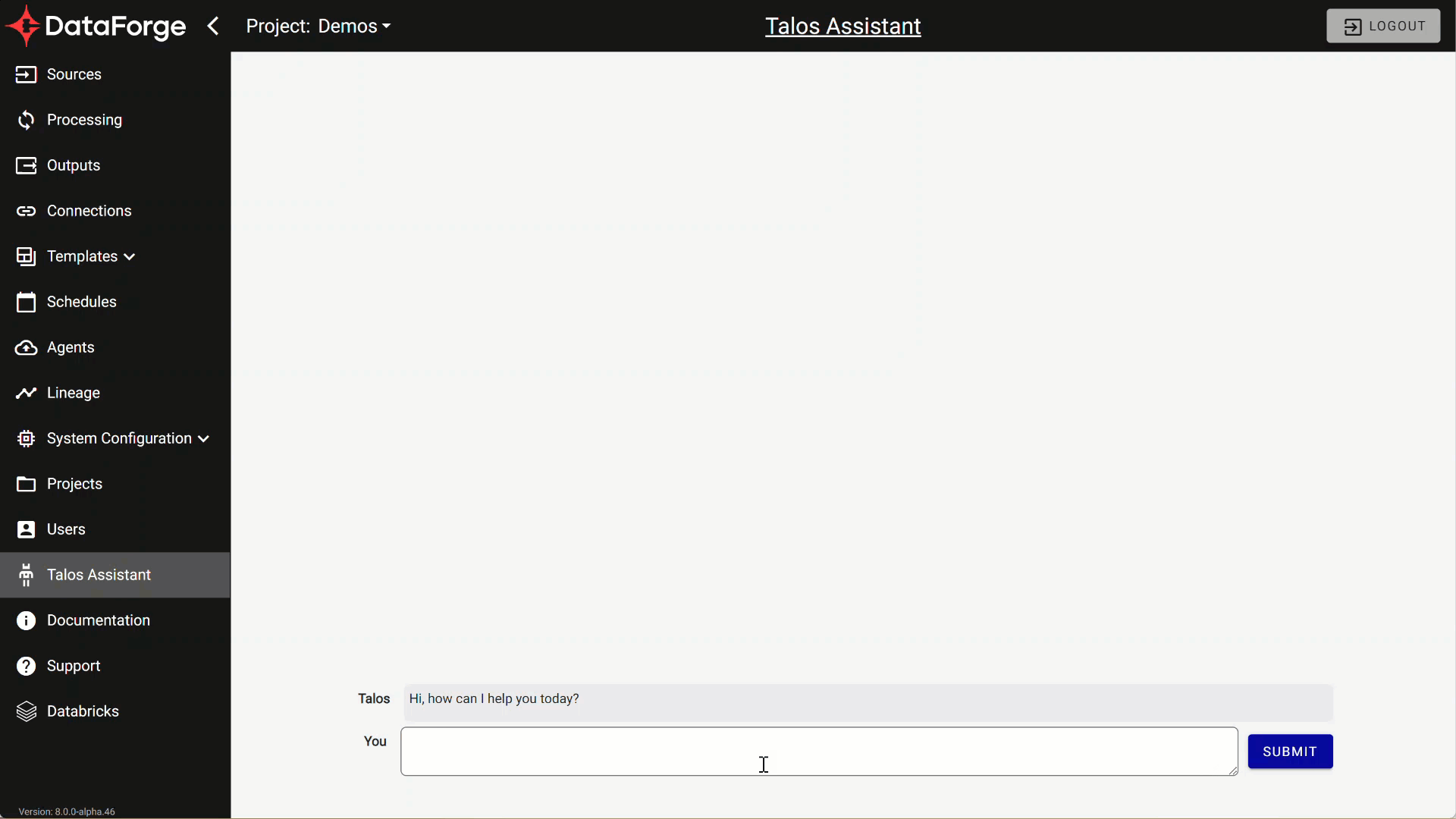
DataForge is excited to introduce DataForge’s Talos virtual assistant. Here is a list of things Talos can help with:
- Find Connections by name
- List & search schemas and tables within metadata for the connection
- Create source and pull data from table(s)
- Find a source and open it
- Find an attribute (raw, rule, or output column) and open lineage for it
Talos is available in preview for DataForge Cloud Professional and Enterprise (AWS only) customers.
DataForge Cloud 8.0 is here to transform your data operations with advanced features and user-friendly enhancements. Upgrade now and experience the future of data management with DataForge!
Ready to try DataForge?
Start with the Community plan — free forever — or talk to our team.