DataForge Platform
Ember
A prescriptive data catalog for scalable platforms
Ember is DataForge's prescriptive data catalog — the system of record for how data is shaped, validated, and interpreted across the platform.
Unlike traditional catalogs that observe data after the fact, Ember is prescriptive by design. It captures intent as declarative logic and applies it consistently across pipelines so meaning does not fragment as the platform scales.
| source_name | conn_type | rules | last_run | runs_30d |
|---|---|---|---|---|
| Coins - JCCosttran | table | 138 | 2025-05-11 06:12 | 31 |
| Linc - vSMAgreement | file | 132 | 2025-05-11 06:14 | 31 |
| Linc - vSMWorkOrder | file | 110 | 2025-05-11 06:15 | 31 |
| RieckC - SEOrderVal | table | 96 | 2025-05-11 06:13 | 28 |
| Linc - vSMDetailTxn | file | 69 | 2025-05-11 06:16 | 31 |
Catalogs That Observe Do Not Scale
Catalogs That Prescribe Do
Traditional data catalogs are built to document what already exists. They scan schemas, collect descriptions, and surface metadata after pipelines are deployed.
This works early. It breaks as pipelines multiply and logic diverges.
Ember was built for the opposite problem.
Traditional Catalogs
- Observe data after the fact
- Document outcomes rather than intent
- Track tables and rows, not logic
- Drift as pipelines evolve independently
- Require manual governance to stay accurate
Ember
- Defines intent before pipelines run
- Prescribes how data should behave
- Applies rules consistently across pipelines
- Keeps meaning stable as complexity grows
- Built-in governance — no manual effort required
Because Ember defines behavior rather than recording outcomes, it becomes part of how pipelines are built and operated, not a system consulted after the fact.
With Ember, the data platform has a true system of record — an explicit source of truth for how data is defined and processed.
Where Definition Meets Execution
Every declarative rule defined in Ember is linked to the pipelines that run it and the outcomes those pipelines produce. Execution details are not inferred or stitched together from external systems.
Define
Rules, sources, and validations are declared explicitly in Ember — not embedded in pipeline code.
Execute
Pipelines run automatically from Ember definitions. Dependencies are implicit. Orchestration is never manually defined.
Observe
Execution metadata, timing, lineage, and outcomes are captured automatically and tied back to the definitions that produced them.
What Ember captures
- Declarative definitions for data shape, rules, and validation
- How declarative logic executes within the single enforced pipeline architecture defined by Alloy
- Execution metadata including timing, dependencies, and outcomes
- Lineage that reflects actual transformations, not inferred guesses
Because definition and execution are stored together, Ember becomes the authoritative source for understanding how data behaves across the entire platform.
Column lineage — live from DataForge
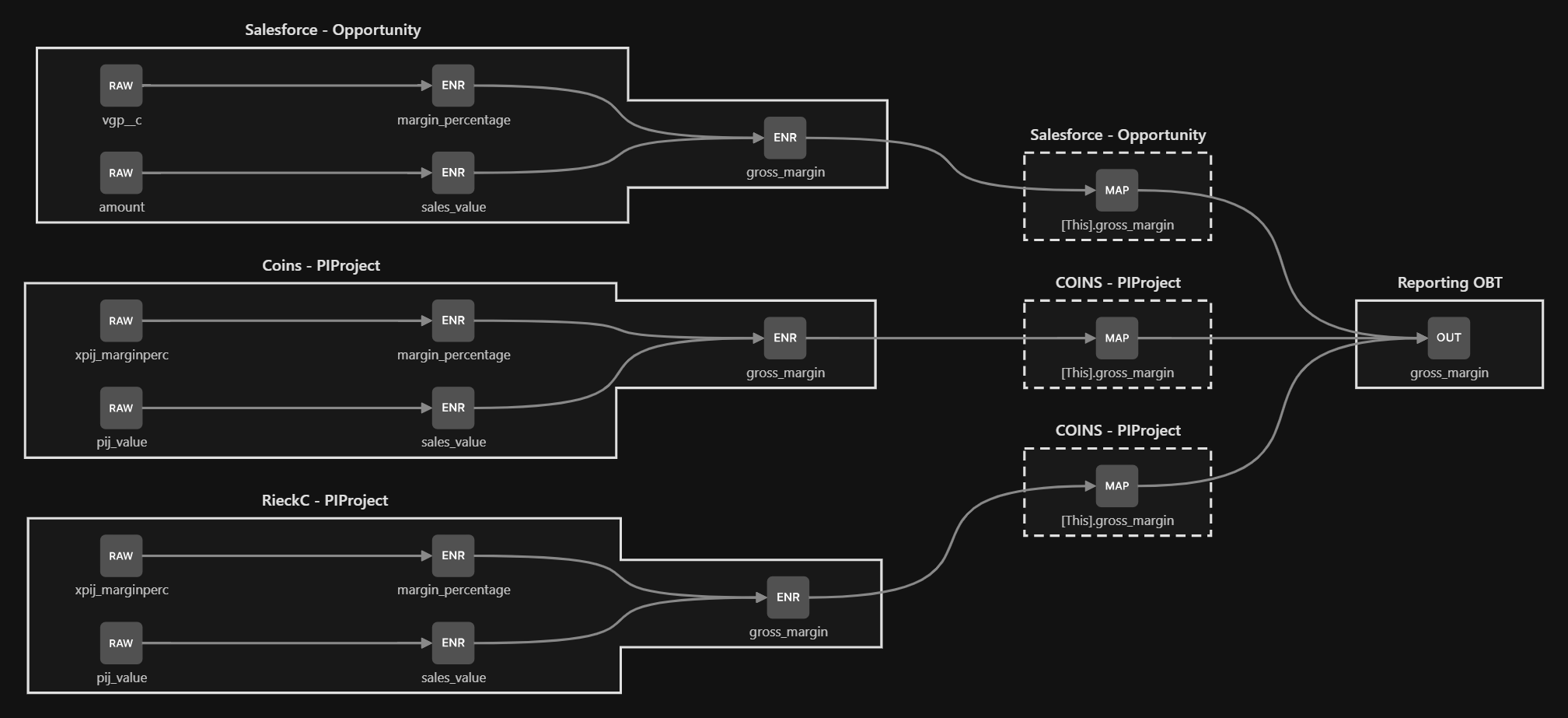
Lineage is captured automatically — no manual mapping required.
Understand Pipelines Without Reverse Engineering
In most data platforms, understanding pipeline behavior requires custom logging, external observability tools, and manual investigation. In Ember, visibility is automatic and always accurate.
Because logic is declarative and execution is standardized, Ember captures operational detail as pipelines run. There is no need to instrument pipelines or reconstruct behavior from scattered logs.
What teams can see by default
- Which rules and transformations ran
- Where logic succeeded or failed
- How long each step took
- What downstream data was affected
Pipeline process log — live from DataForge
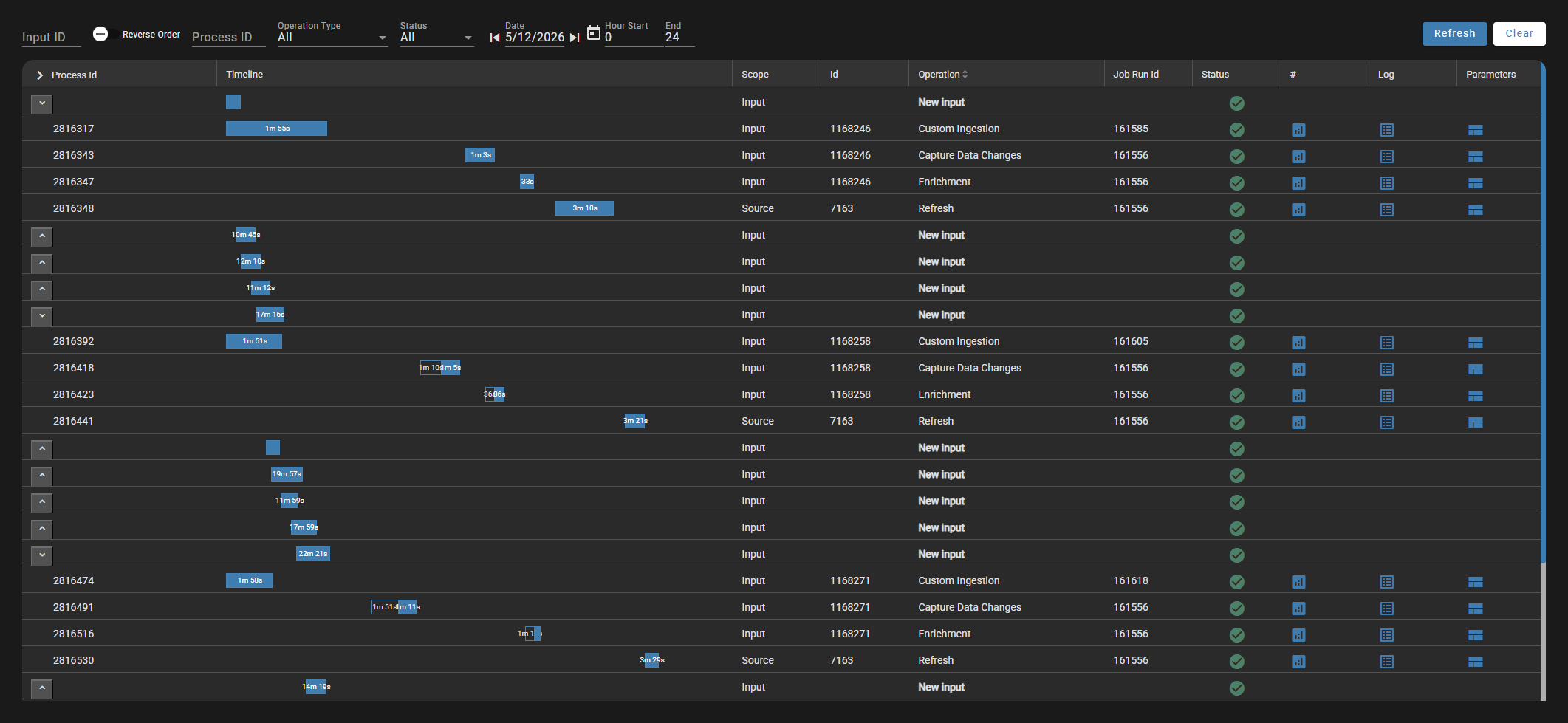
Every step — timing, scope, operation, and status — captured without instrumentation.
Why this matters
When teams can see what happened and why, they debug faster, onboard new developers more easily, and make changes with confidence.
Operational clarity is not a feature — it is a consequence of a well-defined system.
The Queryable Catalog
Everything is SQL. Everything is Queryable.
Every configuration, rule, and execution record in Ember lives in a Postgres database. The meta schema holds all pipeline configuration. The history schema holds all execution records. Both sit in the same database — directly cross-queryable. No separate APIs. No dashboards to export. No log pipelines to build.
Every rule change is automatically recorded with who changed it and when. No instrumentation required.
Config and execution history in a single cross-schema join. Replaces external log analytics and monitoring pipelines.
Stored procedures traverse the full dependency graph and return the complete lineage chain as a tabular result set.
Logic Has a Shape
Ember does not allow logic to be defined arbitrarily. Every rule, transformation, and validation must conform to a small set of explicit, structured patterns — defined declaratively, attached to known entities, scoped to specific stages.
What this structure enforces
- Logic must be defined declaratively, not embedded ad hoc in pipelines
- Transformations attach to known entities and lifecycle stages
- The unit of work is fixed and consistent across all pipelines
- Custom code is allowed only in controlled, explicit locations
Without Ember vs. With Ember
This constraint is intentional.
Custom code is supported, but only in clearly defined extension points. It operates within the same structural boundaries rather than redefining how the pipeline works.
The architecture is predetermined.
Logic simply slots into a known structure. Meaning remains consistent. Execution remains predictable.
The result
- Dependencies are always implicit
- Orchestration is never manually defined
- Pipeline design disappears as a concern
- Complexity grows without multiplying workflows
This is a subtle advantage in small systems. At scale, it is a fundamental shift.
Built for Automation at Scale
How Talos and Ember work together
Ember is not just a catalog that documents what happened.
It is a prescriptive definition layer that replaces pipeline design itself.
The same constraints that allow large engineering teams to scale without chaos are what make AI-driven automation possible.
"Ember works because it removes choice where choice creates fragmentation."
- Logic has a fixed shape.
- Execution follows a single model.
- Definitions are explicit and shared.
Talos is DataForge's AI control plane that translates natural language into Ember's structured definitions. When something does not conform, Ember responds exactly as it would for a human developer — by rejecting it.
There is no special path for AI. Ember is built to support both developers and AI from the ground up.
Ember is the missing bridge between large language models and fully automated data pipelines.
Solution guides
Evaluate DataForge by platform goal
Enterprise data platform
Enterprise data platform for governed analytics at scale
DataForge helps CDOs, CFOs, and data platform leaders scale analytics without assembling separate ETL, orchestration, observability, lineage, and cost-control tools.
Data pipeline platform
Data pipeline platform for complex enterprise source systems
DataForge helps data teams build, extend, orchestrate, and observe enterprise data pipelines while preserving a consistent architecture across every source and output.
Data engineering platform
Data engineering platform with architecture built in
DataForge gives data engineering teams a structured platform for pipeline logic, orchestration, observability, and governance without forcing data outside the client cloud.
Data orchestration platform
Data orchestration platform without manually assembled DAG sprawl
DataForge orchestrates data pipelines from structured pipeline definitions, dependency metadata, scheduling, and execution history instead of manually maintained DAGs.
Data observability platform
Data observability platform with lineage, quality, audit, and cost context
DataForge observability ties code, orchestration, quality rules, alerts, lineage, audit trails, and cloud cost visibility back to the platform metadata.