Advanced SQL ConceptsSQL Recursive Hierarchy Query: Key Concepts
Multi-chapter guide | Chapter 6
SQL recursive hierarchy queries support processing hierarchical or tree-structured data through self-referencing. At the core of these queries lies the Common Table Expression (CTE), a feature that provides a temporary result set within a larger query. Recursion in a CTE allows you to repeatedly reference a result set to traverse levels in the hierarchy until a specific condition is met.
This article dives into the mechanics of SQL recursive CTEs and discusses techniques to optimize their performance with practical examples.
Summary of key concepts of SQL recursive hierarchy query
| Concept | Description |
|---|---|
| Common Table Expression (CTE) | Provides a temporary result set within a larger query. Standard, multiple, and nested CTEs allow you to break down complex SQL queries into manageable, reusable parts. |
| Recursive CTE syntax | Three main components—anchor member, recursive member, and terminator. |
| Infinite recursion and cycle detection | Termination check in the query and cycle detection stop the recursion and avoid endless loops |
| Optimize recursive query |
|
| Concurrency and recursive queries | Selecting the right isolation levels, optimizing the query's structure, and managing concurrency help create balance. |
Common Table Expression (CTE) overview
A Common Table Expression (CTE) is a named result set generated from a SELECT statement, existing only within the scope of the parent query. This temporary result set can be referenced multiple times within the main query, making it easier to structure and understand complex logic. It enhances SQL code readability and reusability.
In the example below, we initially create an Employee table and then populate it with some data, including name, department, and salary. The CTE finds the top earners.

CREATE TABLE Employees (
Name VARCHAR(100),
Department VARCHAR(100),
Salary Int
);
INSERT INTO Employees (Name, Department, Salary)
VALUES
('Sam', 'IT', 90000),
('Frank', 'Management', 145000),
('Charlie', 'HR', 70000),
('Sarah', 'IT', 97000),
('Max', 'HR', 66000),
('Lili', 'Management', 120000);
WITH top_earners AS (
SELECT Name, Department, Salary
FROM Employees
WHERE Salary > 95000
)
SELECT * FROM top_earners;
The output is as follows:
| Name | Department | Salary |
|---|---|---|
| Frank | Management | 145000 |
| Sarah | IT | 97000 |
| Lili | Management | 120000 |
CTEs are highly versatile; you can include multiple CTEs in a single query by separating them with commas. Additionally, nested CTEs allow one aggregate function to be used within another, providing a powerful way to perform layered calculations or data transformations.
Some database systems (e.g., PostgreSQL) support parameterized CTEs, which allow the use of variables and function like dynamic queries.
Recursive CTE syntax
Recursion occurs when a function calls itself to solve a problem. In the same way, a recursive CTE (Common Table Expression) refers to itself within a query. Recursive CTEs are particularly useful for processing hierarchical data, such as tree-structured data or graphs representing complex information like organizational charts, network topology, or transport systems, where each element is recursively connected to others.
A recursive CTE is constructed using three essential parts.
The anchor member is the starting point of the recursion and provides the base result set.
The recursive member performs the iterative operation that references the CTE itself.
The termination check ensures that the recursion stops when a specific condition is met, preventing infinite loops and making the process efficient.
As a simple example, we write a recursive CTE to find numbers below 50 divisible by 7.
WITH RECURSIVE divisible_by_seven AS (
SELECT 7 AS num -- anchor member
UNION ALL
SELECT num + 7 FROM divisible_by_seven -- recursive member
WHERE num + 7 < 50 -- terminator
)
SELECT num FROM divisible_by_seven; -- invocation
The anchor member initializes the recursion by selecting the number 7 (the first number divisible by 7). The next part is the recursive member, which takes the value of num from the previous iteration and adds 7. It continues until the termination check (staying under 50) is met. The invocation results in a list of numbers: 7, 14, 21, 28, 35, 42, 49.
SQL recursion example for hierarchical data
A hierarchical data structure organizes data in a tree-like format, where each element has a single parent node and zero or more child nodes. This structure clearly represents relationships between elements, with each item linked to its predecessor in a parent-child relationship. Hierarchical data structures are frequently utilized in various applications, such as organizational charts, file systems, and taxonomies, where relationships between entities follow a defined non-circular path.
In the following example, the hierarchical relations for some European tourist destinations are stored so that each element is represented with a row that includes the parent_id column (the id of their parent node).

In this example, we will build a recursive CTE to find the path for each city shown in the hierarchical data of tourist destinations.
CREATE TABLE tourist_destinations (
id INT,
destination VARCHAR NOT NULL,
parent_id INT
);
INSERT INTO tourist_destinations (id, destination, parent_id) VALUES
(1, 'Europe', NULL),
(2, 'France', 1),
(3, 'Germany', 1),
(4, 'Paris', 2),
(5, 'Nice',2),
(6, 'Berlin',3),
(7, 'Cologne',3),
(8, 'Munich',3);
WITH RECURSIVE destinations_Path AS (
SELECT id, CAST(destination AS text) AS path, parent_id, 0 AS distance
FROM tourist_destinations WHERE parent_id IS NULL
UNION ALL
SELECT td.id, dp.path || '->' || td.destination, td.parent_id, 1 + dp.distance
FROM tourist_destinations td, destinations_Path dp
WHERE td.parent_id = dp.id
)
SELECT path FROM destinations_Path WHERE distance = 2;
In the above query, selecting the Europe row (where parent_id is null) is the anchor member. The recursive member extends the hierarchy by finding child destinations and updating their paths and distances. Finally, in the invocation, we select the rows that traverse two levels from the root destination.
| path |
|---|
| Europe -> France -> Paris |
| Europe -> Germany -> Berlin |
| Europe -> Germany -> Cologne |
| Europe -> Germany -> Munich |
SQL recursion example for transitive closure
Relational databases are commonly used for graph data in applications like social networks and recommendation systems. Graphs consist of vertices and edges, where vertices represent entities or nodes and edges represent the connections or relationships between those nodes.
In a database, vertices are typically stored in one table, while edges, which define the relationships between the vertices, are stored in a separate table. This distinction enables the efficient management of large graph structures, where nodes and their relationships are clearly defined and can be easily queried or updated.
SQL recursive queries can achieve transitive closure by navigating relationships within graph-like data structures. They can retrieve all descendants or connections from a given node, allowing the traversal of the graph from one node to any other reachable node. You can produce results that reflect the entire set of connected nodes.
The example below creates a recursive CTE that identifies the most environmentally friendly route to visit all five cities in the graph below. The path with the shortest total flight distance results in the lowest CO₂ emissions.
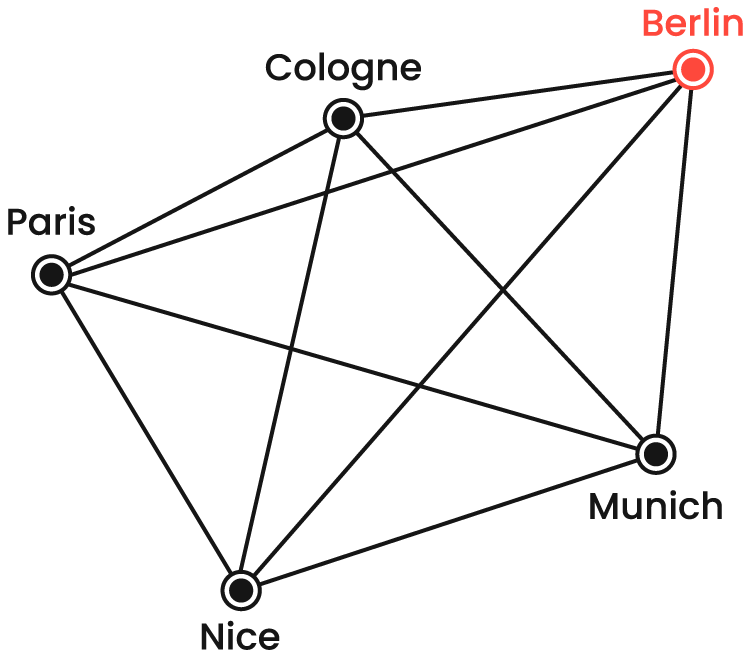
CREATE TABLE cities (
city VARCHAR(100),
longitude DECIMAL(9,6),
latitude DECIMAL(9,6)
);
INSERT INTO cities (city, longitude, latitude) VALUES
('Berlin', 13.4050, 52.5200),
('Munich', 11.5820, 48.1351),
('Cologne', 6.9603, 50.9375),
('Nice', 7.2619, 43.7102),
('Paris', 2.3522, 48.8566);
WITH RECURSIVE flight(path, prev_latitude, prev_longitude,
flight_distance, count_cities) AS (
SELECT
CAST(city AS text), latitude, longitude, CAST(0.0 AS FLOAT), 1
FROM cities
WHERE city = 'Berlin'
UNION ALL
SELECT
flight.path || '->' || cities.city,
cities.latitude,
cities.longitude,
flight.flight_distance +
2 * 6371 * ASIN(SQRT(
POWER(SIN(RADIANS(prev_latitude - cities.latitude) / 2), 2) +
COS(RADIANS(cities.latitude)) * COS(RADIANS(prev_latitude)) *
POWER(SIN(RADIANS(prev_longitude - cities.longitude) / 2), 2)
)),
flight.count_cities + 1
FROM cities, flight
WHERE position(cities.city IN flight.path) = 0
)
SELECT path, ROUND(CAST(flight_distance AS NUMERIC), 2) AS flight_distance_km FROM flight
WHERE count_cities = 5
ORDER BY flight_distance ASC
LIMIT 5;
The anchor member is the starting city (Berlin). In the recursive member, we append the current destination's name to the path, calculate the distance between the current edge (city) and the previous one, and add to the total distance. We also count the number of cities in each recursion so that when invoking, we can select paths involving all five cities (count_cities = 5). Ultimately, we order the results by flight distance to find the most environmentally friendly route with the shortest path.
| path | flight_distance_km |
|---|---|
| Berlin->Munich->Cologne->Paris->Nice | 2048.76 |
| Berlin->Cologne->Paris->Munich->Nice | 2159.18 |
| Berlin->Cologne->Paris->Nice->Munich | 2159.89 |
| Berlin->Munich->Nice->Paris->Cologne | 2187.04 |
| Berlin->Cologne->Munich->Nice->Paris | 2213.19 |
Simplifying SQL recursive query syntax
In practice, the syntax of SQL recursive queries quickly becomes complicated, as it can involve different columns, joins, functions, conditions, etc. Advanced data transformation tools like DataForge reduce complexity using a rule-based format and decomposition. For example, the following code is generated using DataForge. It specifies the source and target tables, their columns, and the transformation rules in a YAML file. It implements a recursive query to build an employee hierarchy.
employees.yaml
source_name: employees
source_query: hr.employees
target_table_name: transformed_employees
raw_attributes:
- emp_id int
- emp_name string
- emp_salary decimal
- emp_manager_id int
rules:
- name: employee_details
expression: "[This].emp_name, [This].emp_salary"
- name: manager_details
expression: "[hr.employees].emp_name"
- name: recursive_hierarchy
expression: |
WITH RECURSIVE employee_hierarchy AS (
SELECT emp_id, emp_name, emp_salary, emp_manager_id
FROM hr.employees
WHERE emp_manager_id IS NULL
UNION ALL
SELECT e.emp_id, e.emp_name, e.emp_salary, e.emp_manager_id
FROM hr.employees e
JOIN employee_hierarchy eh ON eh.emp_id = e.emp_manager_id
)
SELECT * FROM employee_hierarchy;
departments.yaml
source_name: departments
source_query: hr.departments
target_table_name: transformed_departments
raw_attributes:
- dept_id int
- dept_name string
- dept_head_id int
relations.yaml
relations:
- name: "[hr.employees]-emp_manager_id-[hr.employees]"
expression: "[This].emp_id = [Related].emp_manager_id"
- name: "[hr.employees]-dept_head_id-[hr.departments]"
expression: "[This].emp_id = [Related].dept_head_id"
Infinite recursion and cycle detection
A database generally does not automatically stop a recursive query and results in an infinite loop leading to stack overflow, where the system runs out of memory. You can prevent this issue by manually defining a termination check within the query. The terminator acts as a safeguard, ensuring the recursion stops when a termination condition is met, such as reaching a specific value or exceeding a defined threshold.
Sometimes, cycles or interlinked data loops in hierarchical or graph-like data can prevent the termination condition from being reached. PostgreSQL (version 14 and above) directly supports the CYCLE clause for detecting such cycles in recursive queries.
For example, consider a table called relationships storing organizational hierarchy. Each row represents an employee, and the superior_id indicates which employee the current one reports to. The code below shows a recursive CTE with cycle detection to check if there’s any cycle in the "path" hierarchy:
CREATE TABLE relationships (
id INT,
title VARCHAR NOT NULL,
superior_id INT
);
INSERT INTO relationships (id, title, superior_id) VALUES
(1, 'CEO', NULL),
(2, 'Head A', 1),
(3, 'Head B', 1),
(4, 'Employee 1', 2),
(5, 'Employee 2',2),
(6, 'Employee 3',3),
(7, 'Employee 4',3),
(1, CEO', 2); -- creating a loop
WITH RECURSIVE hierarchy_Path(id, path, superior_id) AS (
SELECT id, CAST(title AS text) AS path, superior_id
FROM relationships
WHERE title = 'CEO'
UNION ALL
SELECT r.id, h.path || '->' || r.title, r.superior_id
FROM relationships r
JOIN hierarchy_Path h ON r.superior_id = h.id
)
CYCLE id SET is_cycle USING cycle_path
SELECT DISTINCT(path)
FROM hierarchy_Path
WHERE is_cycle = false;
In this example, we have introduced the last element again but with a different relationship to create a loop. The line with the CYCLE clause marks the id as a cycle if it encounters the same id during recursion. The CYCLE clause detects the cycles during the recursive process and prevents infinite recursion. The CAST ensures consistent data type (text) for recursive concatenation as the title has VARCHAR type.
The query returns the finite list below.
| path |
|---|
| CEO |
| CEO->Head A |
| CEO->Head B |
| CEO->Head A->Employee 1 |
| CEO->Head A->Employee 2 |
| CEO->Head B->Employee 3 |
| CEO->Head B->Employee 4 |
SQL recursive hierarchy query optimization
Consider the following when optimizing recursive queries.
Apply early WHERE clauses
It's essential to apply WHERE clauses early in the CTE so that each recursion processes smaller data sets and becomes more efficient. The recursive query avoids unnecessary iterations over large data volumes by filtering the data as early as possible.
Set recursion depth
Setting a recursion depth limit using the MAXRECURSION option in SQL Server ensures the query terminates after a specified number of recursive calls. You prevent excessive resource usage, and avoid the risk of infinite loops.
Index key columns
Creating indexes on key columns in recursive CTEs, especially on join conditions, enhances lookup speed and overall query performance. Indexes allow the database to quickly locate relevant rows during each recursive iteration, significantly speeding up the query execution.
Monitor execution plans
It is essential to monitor the query execution plan and assess resource consumption, such as CPU and memory usage, to identify costly operations. You can then pinpoint inefficiencies, optimize indexing, or adjust query structure to reduce resource-intensive steps.
In the following example, we use EXPLAIN ANALYZE to compare execution time and CTE scan for indexed and non-indexed recursive queries in SQL.
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
title VARCHAR(100),
superior_id INT
);
INSERT INTO employees (title, superior_id) VALUES
('Manager', NULL),
('Employee A', 1),
('Employee B', 1),
('Employee C', 2),
('Employee D', 3);
-- Create an index on the superior_id column to make the recursive query faster
CREATE INDEX idx_superior_id ON employees(superior_id);
EXPLAIN ANALYZE
WITH RECURSIVE hierarchy AS (
SELECT id, title, superior_id,
CAST(employees.title AS text) AS supervision_path
FROM employees
WHERE title = 'Manager'
UNION ALL
SELECT e.id, e.title, e.superior_id,
h.supervision_path || '->' || e.title AS supervision_path
FROM employees e
INNER JOIN hierarchy h ON e.superior_id = h.id
)
SELECT * FROM hierarchy;
The table below shows the result of the hierarchy recursive CTE.
| id | title | superior_id | supervision_path |
|---|---|---|---|
| 1 | Manager | null | Manager |
| 2 | Employee A | 1 | Manager->Employee A |
| 3 | Employee B | 1 | Manager->Employee B |
| 4 | Employee C | 2 | Manager->Employee A->Employee C |
| 5 | Employee D | 3 | Manager->Employee B->Employee D |
Another element that EXPLAIN ANALYZE shows is the cost of the scan (reported in arbitrary units), in terms of CPU usage, memory consumption, and disk input/output. The result below shows how indexed and non-indexed SQL recursive queries differ in performance for the above operation.
| Example | Execution Time | CTE Scan Cost |
|---|---|---|
| Indexed recursive query | 0.069 ms | 16.33 |
| Non-indexed recursive query | 0.196 ms | 175.74 |
Concurrency and recursive queries
Recursive queries are often used in real-time data systems, For instance, a recursive query could retrieve all replies to a specific comment to ensure that each user's comment actions, such as posting a new comment or replying to an existing one, are handled efficiently and in real time.
However, in recursive queries, each step usually relies on the result of the previous recursion. This creates a chain in which the outcome of one step impacts the subsequent step. This dependency presents challenges in concurrent environments. For example, if another query locks the required data or modifies it during execution, it can cause delays, errors, or failures.
In databases, concurrency is managed by setting transaction isolation levels, which determine how transactions interact with each other and the database. They create the following challenges.
Higher isolation levels, such as serializable, lower inconsistency risk but may cause delays or blockages.
Lower isolation levels, like read uncommitted, increase concurrency with more simultaneous operations but may affect data consistency in recursive queries.
Therefore, proper transaction and lock management is crucial for concurrent recursive queries. Optimistic concurrency control improves concurrency in recursive queries by allowing transactions to run without immediate locking. It checks consistency only at the end, boosting performance in low-contention situations.
Code example
The example shows a SQL recursive hierarchy query for a chat application that maintains concurrency safety through proper transaction management and isolation levels.

First, we create a table for comments and insert some messages and replies. The messages represent the image above.
CREATE TABLE comments (
name VARCHAR(50) NOT NULL,
message_id INT PRIMARY KEY,
parent_id INT NULL,
message_text TEXT NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
INSERT INTO comments (name, message_id, parent_id, message_text, created_at) VALUES
('Alex', 1, NULL, 'Hi! Welcome to the discussion. I am Alex, your host!', '2024-12-09 10:00:00'),
('Sam', 2, 1, 'Thanks Alex! I am new here.', '2024-12-09 10:00:10'),
('Lili', 3, 1, 'Looking forward to sharing ideas with you Alex.', '2024-12-09 10:00:20'),
('Sarah', 4, 2, 'Same here! I registered today.', '2024-12-09 10:00:30'),
('Max', 5, 2, 'Me too! Any idea about the topic?', '2024-12-09 10:00:40'),
('Alex', 6, 5, 'Great question! Let's brainstorm together.', '2024-12-09 10:00:50');
Then, we set the highest level of transaction isolation (SERIALIZABLE) to ensure no other transaction can read or modify the data being used by this transaction until it is complete.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
After that, we begin a new transaction. All subsequent operations are performed as part of this transaction and won't be visible to others until the transaction is committed.
BEGIN TRANSACTION;
We have the following recursive CTE to fetch all messages and replies to build a hierarchy of comments:
WITH RECURSIVE comment_hierarchy AS (
SELECT
c.name,
c.message_id,
c.parent_id,
SUBSTRING(c.message_text FOR 15) || '...' AS combined_message_text,
c.created_at
FROM comments c
WHERE c.message_id = 1
UNION ALL
SELECT
c.name,
c.message_id,
c.parent_id,
ch.combined_message_text || ' -> ' || SUBSTRING(c.message_text FOR 15) || '...' AS combined_message_text,
c.created_at
FROM comments c
INNER JOIN comment_hierarchy ch ON c.parent_id = ch.message_id
)
SELECT name, combined_message_text AS message_text_with_parent
FROM comment_hierarchy ORDER BY created_at;
In the end we finalize the transaction using COMMIT, making changes visible to others. If an error occurs before this, the transaction is aborted, and no changes are applied.
COMMIT TRANSACTION;
The query output:
| name | message_text_with_parent |
|---|---|
| Alex | Hi! Welcome to ... |
| Sam | Hi! Welcome to ... -> Thanks Alex! I ... |
| Lili | Hi! Welcome to ... -> Looking forward... |
| Sarah | Hi! Welcome to ... -> Thanks Alex! I ... -> Same here! I re... |
| Max | Hi! Welcome to ... -> Thanks Alex! I ... -> Me too! Any ide... |
| Alex | Hi! Welcome to ... -> Thanks Alex! I ... -> Me too! Any ide... -> Great question!... |
Last thoughts
Although SQL is straightforward and recursive CTEs are meant to improve readability, SQL queries can get complex quickly. For example, complex graph data requires deep recursion, making SQL inefficient and resource-intensive on large datasets. Managing complex queries that impact business logic without version control poses various challenges.
Technologies like DataForge offer modularity and reusability. DataForge improves code maintainability by allowing changes to small components without requiring a complete understanding of the complex transformation. Most data transformation tools enable developers to create reusable components scoped to individual tables. DataForge lets developers narrow modularity down to the cell, row, or column level, making it easier to maintain, debug, and test.