November 5, 2024
Data Transformation at Scale: Rule Templates & Cloning
Tackling common data transformation challenges like repetitive coding and platform complexity.
Preface
As we outlined in Introduction to the DataForge Declarative Transformation Framework blog, using declarative, column-pure transformations in data pipelines allows engineers to take advantage of inheritance and object composition in data engineering. These foundational computer science concepts have been used in software engineering for decades, but have yet to gain wide adoption within the data engineering discipline. They are the key ingredients for successfully building, maintaining and extending large and complex software products with millions lines of code.
The historical inability to apply these concepts to data engineering pipelines often leads to an explosion of spaghetti code that’s been copy-pasted and tweaked multiple times, which geometrically increases the complexity of the data platform. This leads to rampant increase in costs to support and extend your data platform, requiring more effort, resources, and talent.
In this blog and linked video, I will showcase multi-layered mechanisms for centralized transformation code management and re-use available in DataForge Cloud
Rule Template
A Rule Template is an abstract, column-pure function that has properties identical to a Rule. It is created as an abstract object, and initially not linked to any Source. When the rule template is applied to the source, the system validates that rule expression is valid in the context of the source and then creates a new rule in that source. The rule is linked to the template and cannot be modified directly.
The rule template is analogous to the single-method trait or mixin in software engineering. It allows centralized definition and management of transformation logic that is common for multiple data sources.
When the Rule Template changes, all rules linked to the template are automatically updated.
Relation Template
A Relation Template is an abstract, column-pure, boolean-typed function that has properties similar to a Relation. Similar to Rule Templates, they are created as an abstract object, and initially not linked to any pair of sources.
When the relation template is applied to the source, the system validates that the expression is valid in the context of the both sources, and then creates a new relation between them. The created relation is then linked to the template and cannot be modified directly.
Similar to Rule Templates, Relation Templates are analogous to a mixin and enable centralized management of relations between sources with identical logic.
Relation Templates are used to support Rule Templates that include Source Traversals to leverage Rules or Raw Attributes from other Sources.
Token
A Token represents a variable that can be used in any expression (Rule, Relation, and Template counterparts) in 2 ways:
- as constant value
- as complete or partial attribute alias in the expression
Token values are defined for each source. When the rule or relation template is applied to the source, the token value defined for the target source is substituted in the template expression.
Examples:
| Token Type | Template Expression | Token Value (for a specific Source) | Result after compilation |
|---|---|---|---|
| Constant Token | '${CodePrefix}' || [This].code |
PR |
'PR' || [This].code |
| Attribute alias Token | [This].${PhaseCode}_cost |
assembly |
[This].assembly_cost |
Groups and Cloning
Similar to the module concept in programming, a Group organizes multiple sources, outputs, and connections with preconfigured transformations together. When a Group is Cloned, the system creates copies of all objects contained within the Group, replacing their names according to the new group name and source, output or connection template for each object. Group object includes a special type of Token (variable) reserved for use in a source, output, or connection names. Diagram below illustrates cloning of GroupA into GroupB:
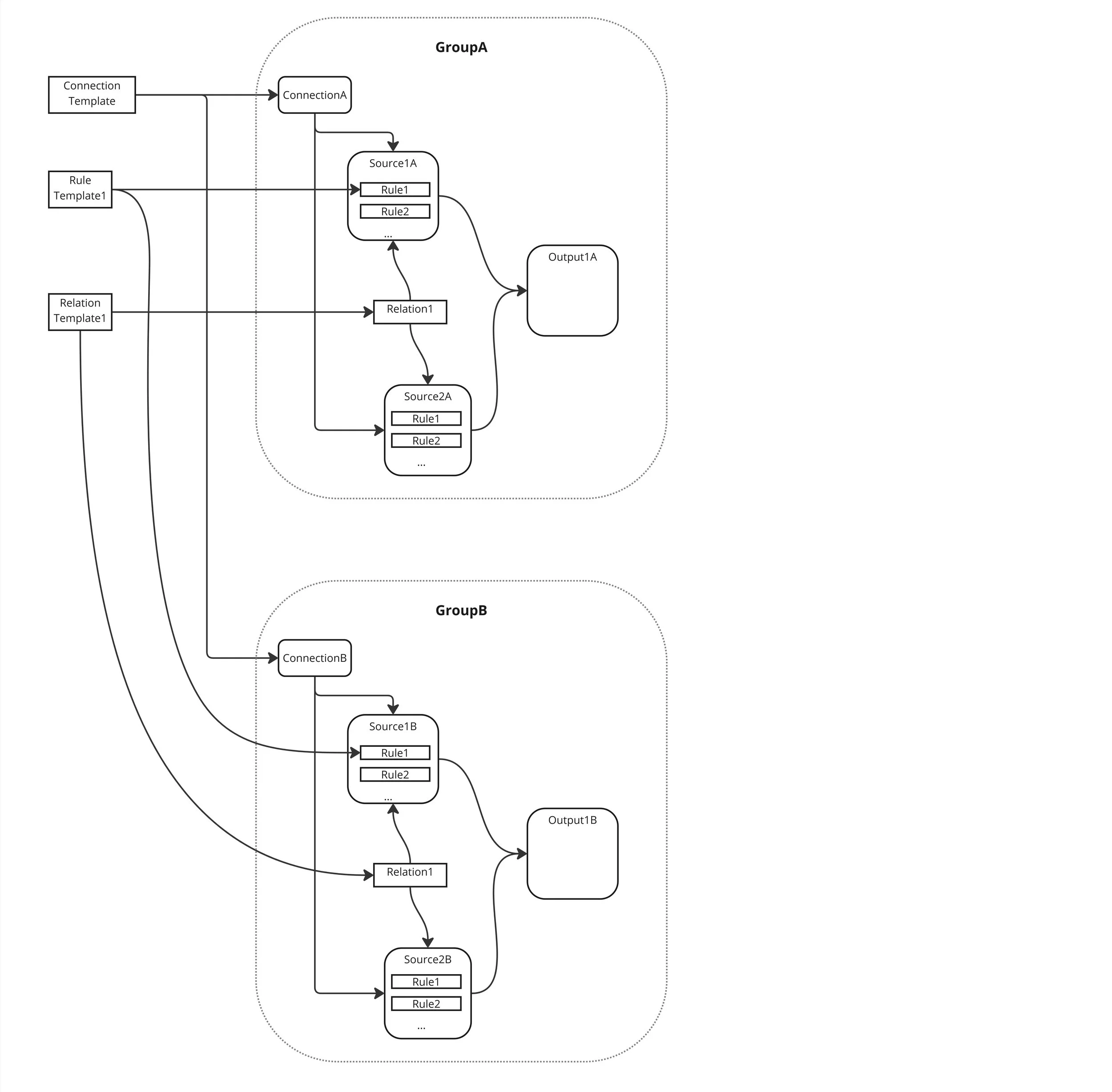
Here is the breakdown of the steps that happen during a Clone operation:
- User selects Group A as the base and instructs DataForge to Clone the Group
- ConnectionB is Cloned from ConnectionA
- Two new sources Source1B and Source2B are Cloned from GroupA sources Source1A and Source2A. This includes all source settings and rules (both templated and regular)
- Relation1 between Source1 and Source2 is Cloned and linked to Relation Template1
- Output1B is Cloned from Output1A, including all channels and mappings
Groups and cloning are commonly used when you have multiple data feeds from similarly structured source systems (e.g. ERP or CRM). Each additional feed can be easily Cloned with a couple clicks, while allowing you to tweak, add or override specific rules and transformations that are unique for each source system. This is similar to importing a module from the library and extending it to accommodate your specific requirements. This mechanism enables centralized management of common transformation logic via rule and relation templates, while providing flexibility to adjust each group via tokens and regular, non-templated rules.
Source and Output Template
Source and Output Templates provide a naming mechanism that ensures uniqueness of source/output name in the project when cloning a Group. These templates are especially important when you want to control if a Cloned Output writes to the same target table(s) as the base Group, or create a new set of target tables specific to the generated Group within the same target database/connection.
Connection Template
Connection Templates allow for cloning of the connection referenced by Sources and Outputs within the Group. When a group is cloned, all templated connections are also cloned. A user just needs to update the cloned connection to point it to the new source/output system. Connection Templates help when the new cloned Group should ingest or write data from/to a different server or database.
Conclusion
Templates, Tokens and Groups provide a powerful, multi-layered mechanism for centralized management of data transformation code. It is based on the established concepts that have been successfully used in software engineering for multiple decades: inheritance, object composition, traits or mixins and modules.
The ultimate benefit it provides is drastically reduced size of the code base in your data platform. This is achieved by enabling DRY principle and reusable code architecture, which eliminates traditionally used copy-pasting that often leads to bloat and spaghettification of code in data pipeline transformations.
Start scaling out your data codebase today with a 30 day free trial of DataForge cloud.
Ready to try DataForge?
Start with the Community plan — free forever — or talk to our team.