September 24, 2024
Sub-Sources: Simplifying Complex Data Structures with DataForge
DataForge Cloud 8.1 introduced Sub-Sources, simplifying the handling of nested complex arrays.
In DataForge Cloud 8.0, we introduced the ability to work with complex data types in all areas of the product, from ingestion through output. This feature enabled our clients to effectively process semi-structured data like structs and arrays.
In DataForge Cloud 8.1, we’ve taken complex data types functionality to the next level with a new, innovative concept: sub-source.

Problem Statement: Nested Complex Arrays (NCAs) are hard
When a column of data is structured as a nested complex array (NCA) with an ARRAY<STRUCT<..>> data type, it presents a unique set of challenges.
For example, consider the ORDER dataset with the following single row structure expressed in JSON format:
{
“order_id”: 123,
“order_date”: “2022-01-05”,
“customer_id”: 15,
“order_detail”: [
{
“qty”: 1,
“price”: “769.49”,
“productid”: 982,
“product_name”: “Mountain-400-W Silver, 42”
},
{
“qty”: 1,
“price”: “49.99”,
“productid”: 715,
“product_name”: “Long-Sleeve Logo Jersey, L”
},
{
“qty”: 1,
“price”: “24.49”,
“productid”: 859,
“product_name”: “Half-Finger Gloves, M”
},
{
“qty”: 1,
“price”: “69.99”,
“productid”: 867,
“product_name”: “Women's Mountain Shorts, S”
}
]
}The “order_detail” key contains an ARRAY of JSON values, with each element representing details about the ordered product. This structure logically represents a nested ORDER_DETAIL table that is physically stored in the ORDER.ORDER_DETAIL column. ARRAY elements represent rows, and STRUCT keys (qty, price, …) represent columns of the nested table. ORDER and ORDER_DETAIL tables are logically related via 1:M relation. This logical-only relation is implicit by virtue of the order_detail data being contained in the parent ORDER record. Physically this data format is considered denormalized.
This data structure is fairly common in NoSQL databases, Event Hubs, and RESTful API integrations. Although the NCA structure represents a table, standard SQL DML cannot be directly applied to it, as it lacks the syntax to deal with the implicit 1:M relation. Querying and transforming NCA data is a common challenge data engineers face.
There are a couple common solutions to working around this lack of direct syntax support:
Option 1: Normalization
The most common approach is to normalize the data structure into two related tables as illustrated below:
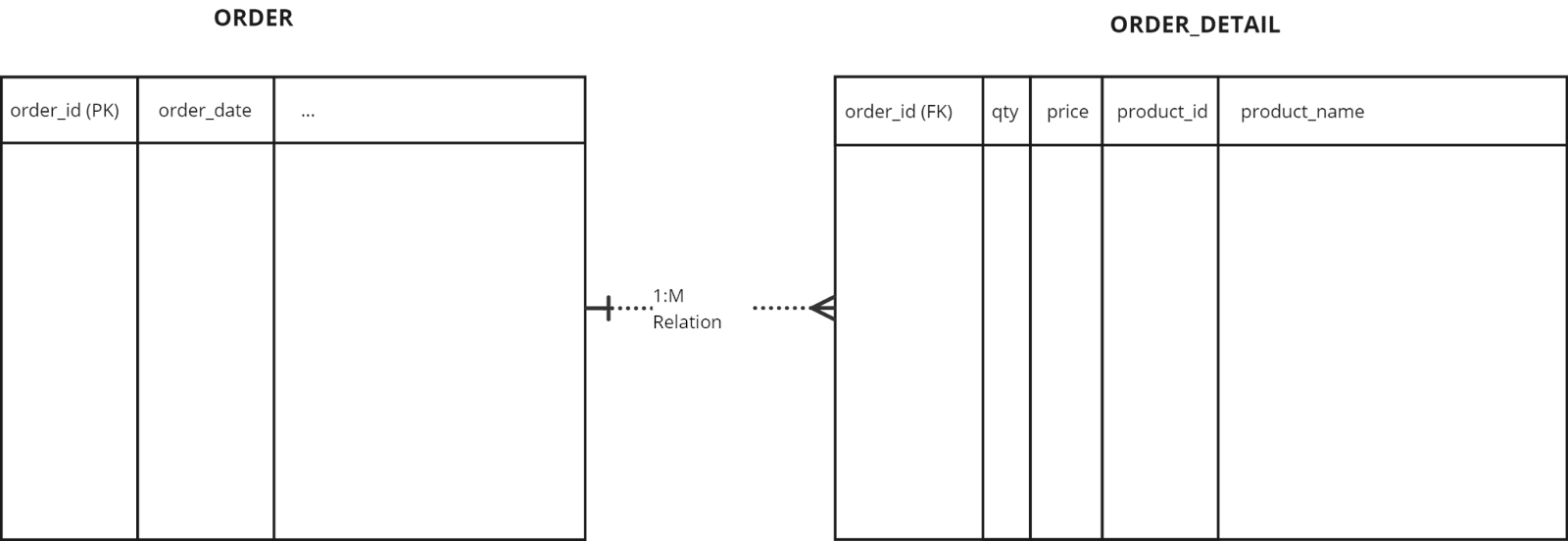
The Normalization process involves the following steps:
- Unnest order_detail array into rows
- Explode json value into individual table columns
- Copy the primary key (order_id) of the parent ORDER record to each row
- Store results in new ORDER_DETAIL table, related to ORDER via M:1 relation on order_id
This approach produces a normalized data structure and enables engineers to use standard SQL operations on the ORDER_DETAIL table.
Normalization is a fairly tedious process with several complications that require extra manual effort:
- When a primary key does not exist on the parent table, it must be generated, stored, and managed on both tables
- When there are multiple layers of nesting without keys, or a mix of keyed/non-keyed NCA, the complexity of key building and management increases exponentially.
- The potential lack of keys to replace the implicit relation of the data structure is why normalization cannot be fully automated and requires a data engineer to design a unique solution for every dataset.
When the dataset changes, e.g. order_detail gets updated with new rows, changes need to be propagated to both tables.
When data structure of the incoming dataset changes, e.g. product_category attribute is added to order_detail, the order_detail schema needs to be updated accordingly
To summarize, normalization solves the problem of accessing and transforming the nested data but it can be a complex and tedious process that is very difficult or often impossible to fully automate.
Option 2: Platform-specific SQL Extensions
For simple transformations limited to single value selections and aggregations, the normalization step can be avoided by using non-standard SQL such as the TRANSFORM lambda function combined with one or more ARRAY functions available in Spark SQL and Snowflake standards.
The major downside of these functions is their unintuitive, non-SQL-style syntax that becomes extremely difficult to read and debug when used for anything but the most basic operations.
The DataForge Solution: Sub-Source Approach
What if you could get all the syntax benefits of the normalization approach without processing the data into physically separate tables? With DataForge, we added a capability to create logically separate tables without physically altering the underlying data structures, allowing engineers to write standard SQL expressions on datasets containing NCAs.
DataForge compiles the logical meta-structure definitions and standard SQL expressions to generate the syntax (such as TRANSFORM functions) to process the NCA in its native format.
More simply: Work with complex datatypes as if they were flat tables with standard SQL syntax without the need for normalization.
Here is how it works in DataForge:
- A Sub-Source is created by defining a DataForge Rule pointing to an existing NCA column in the parent Source.
- A Sub-Source is a “virtual” DataForge Source that reads the data from the parent Sources’ NCA column and writes data to a new target column in the parent Source.
- This process maintains the column-pure nature of Rules while allowing for operations on NCA data elements
- The Sub-Source grain is defined by the NCA array, i.e. the number or elements in the array equals the number of rows in the Sub-Source.
- A Sub-Source is implicitly related to the parent source via M:1 DataForge Relation automatically created by the system.
- Unlike standard SQL JOIN syntax, a DataForge Relation is conceptually flexible enough to natively support this implicit connection between two tables.
- Once created, the new Sub-Source behaves exactly like a normal source for all transformation code such as Rules, Relations, and Mappings within the DataForge framework, allowing for standard SQL-expression syntax to be used.
Here is a diagram showing the new setup in DataForge:
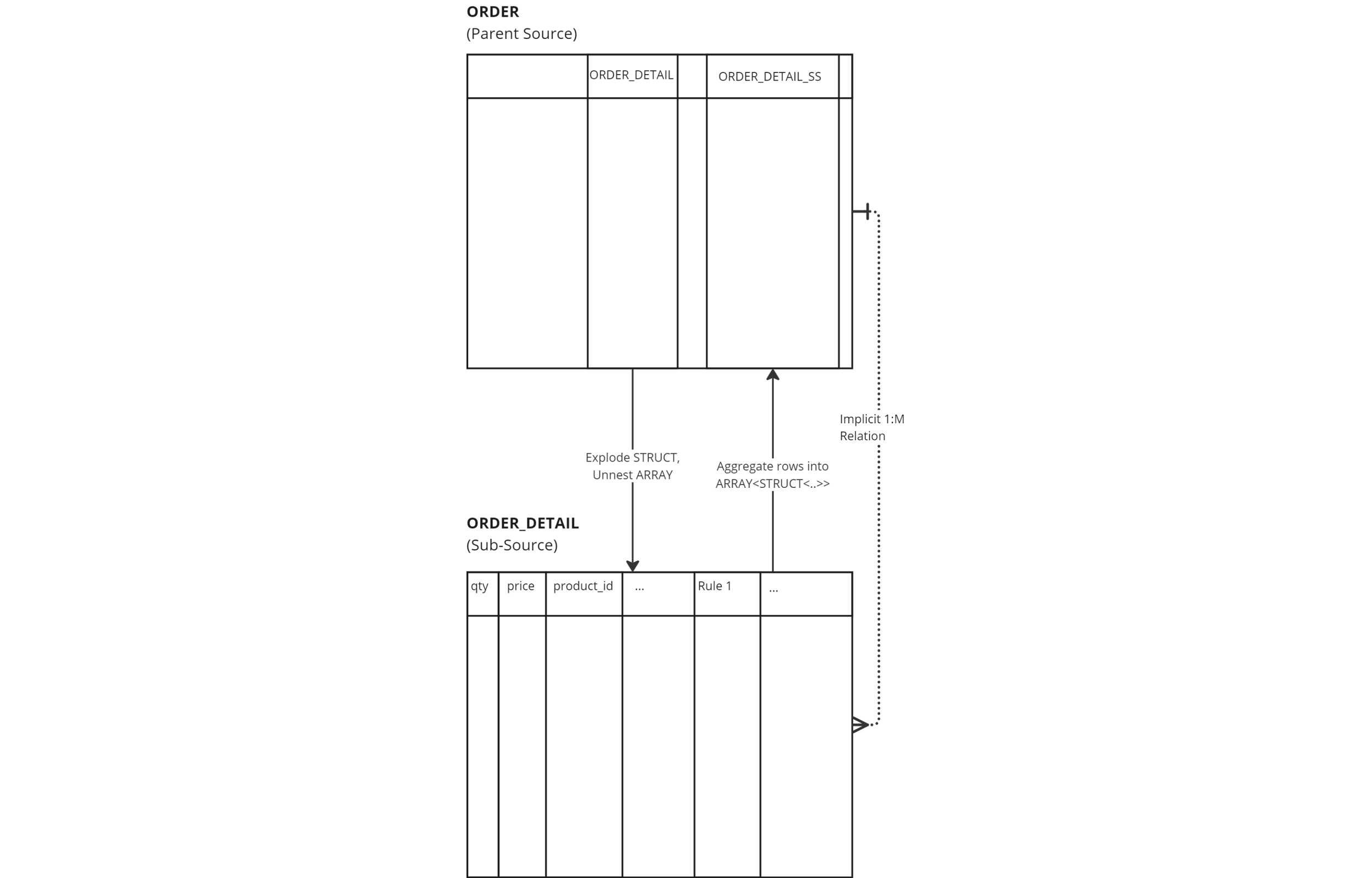
Sub-Sources differ from regular sources in a few ways:
- Data stays physically stored in the parent source table
- The Raw Attribute NCA column is not modified
- Results are stored in the enriched Rule column that defines the Sub-Source
All data processing is performed in the context of the parent source
- Sub-sources share the inputs (batches), process, and log records with the parent source
Refresh type is inherited from the parent source, and operates at the grain of the parent source
Unique rules are not supported within the sub-source
How to use Sub-sources in DataForge:
- Configure relations to other DataForge sources, enabling to pull/push data from/to Sub-Source
- Configure rules within Sub-Source in the same manner as with regular DataForge source. Sub-Source rules can reference attributes from any related source, including Parent.
- Rules created in the sub-source are calculated during parent source processing, and the results are saved into the parent source hub table, within the Sub-Source rule column. Physically, each Sub-source rule adds new STRUCT key to the original STRUCT schema of the NCA column
Define rule in another source that calculates value in the Sub-Source, using available implicit and user-defined relation paths.
- Common use case is aggregating the value contained in the Sub-Source, e.g. SUM([ORDER_DETAIL].qty * [ORDER_DETAIL].price) at the higher level ([Order])
Sub-Sources can be nested at multiple levels: when your data structure contains nested ARRAY<STRUCT<… <ARRAY
Sub-Sources can also be mapped to Output Channels
- When mapped, it will explode/flatten the NCA, allowing for easy normalization and de-nestings in the target system when needed
Conclusion
DataForge Sub-Sources enable a fast and effective way to transform nested semi-structured data, abstracting its complexity. A Sub-Source is virtually identical to regular DataForge Source for all intents and purposes: it supports rules, relations and outputs just like regular Source. Sub-Source data is physically stored in the parent source column, saving data engineers from having to design, build and maintain complex normalization pipelines with additional storage layers and transformations.
Take advantage of this innovative new approach and accelerate your development by starting a 30 day trial of DataForge Cloud today!
Ready to try DataForge?
Start with the Community plan — free forever — or talk to our team.