November 26, 2024
Refresh Strategies in DataForge
Learn the power of DataForge Cloud's refresh patterns to streamline your data pipelines.
What is Refresh in Data Engineering?
Refresh is the process in a data pipeline that consolidates individual batches (or event streams) of data into the most current representation of the dataset (such as the gold layer in a medallion architecture). The Refresh process operates on each non-static dataset within a data platform.
The main purpose of a refresh process is to consolidate multiple batches of data, remove duplicate records, and provide the latest version of the data to downstream consumers.
A few secondary features are:
- Capture the history of changes in dataset over time
- Perform atomic and transactional-style updates to ensure consistent dataset state
- Update data incrementally if possible
- Enable easy reprocessing of data after configuration change or error
- Allow for unload and reload processes to remove, correct, and re-add bad batches of data
- Capture and expose observability metrics such as new, changed, and updated record counts, snapshot timestamps, etc.
The most common approach to refreshing data is a basic truncate-reload pattern, where all data is fully replaced. The second most popular and more performant approach is an incremental data refresh of datasets by leveraging a primary key. An extension of primary key incremental refresh is SCD (Slowly Changing Dimension) Type 1 and 2, where the history of data for each key is tracked in addition to maintaining the most up to date records. This concept was covered in a previous blog where Databricks’ Delta Live Tables and DafaForge Cloud approaches were compared. Before jumping in to this material further, it is likely helpful to review this previous blog first.
Unfortunately, not every data set has a natural primary key. In many tools and architectures, the only way to support incremental refresh with these non-keyed tables is via a custom-developed pipeline and dataset-specific refresh logic.
Refresh Types in DataForge
At DataForge, we are strong believers in column-pure, functional, and declarative transformation logic. Applying these ideals to the universal batch data processing problem of Data Refresh, we developed six different and declaratively-definable refresh patterns:
| Refresh Type | Description |
|---|---|
| Key | Used with datasets having a natural primary key |
| Full | Truncate and reload. Useful for smaller datasets or during development. |
| None | Append-only mode. Used when source data already contains change markers and guaranteed only-once delivery. |
| Timestamp | Used for time-series data |
| Sequence | Similar to time-series, but with numeric sequence counter instead of timestamp |
| Custom | The most flexible option allows to specify custom refresh criteria by providing 2 row-pure functions |
Key Refresh:
Starting with the most commonly used Refresh Type, Keyed Refresh has the following parameters:
Key Refresh Processing steps
- Calculate a hash value of all non-key attributes in the latest batch, excluding columns specified by the “Exclude From CDC” parameter. Store the value in a new system-managed column: s_hash
- For each record, store the value from the Date Column in a new system-managed column: s_update_timestamp
- Compare s_hash and s_update_timestamp values in the current batch with the last received record for each key in the Hub table, and calculate s_record_status_code with one of the following values: N - new C - updated U - unchanged S - unchanged with more recent s_update_timestamp O - old record: updated, but with older s_update_timestamp
- Apply filter of s_record_status_code IN (‘N’,’C’) for the next processing step
- Merge the batch into main dataset (Hub table) by updating changed (‘C’) records, and appending new (‘N’) records
While the key and hash approach is pretty standard and has been widely used in ETL pipelines, the configurable Date Column is fairly unique to DataForge. It enables to accurately identify and filter out “old” records, which have been updated earlier, before the current update timestamp. This ensures accuracy of the most recent record and optimizes processing. It helps in scenarios where input data batches (or files) are received out of order, such as historic data loads.
| Parameter | Description |
|---|---|
| Key Columns | Used with datasets having a natural primary key |
| Exclude From CDC (optional) | List of columns to exclude from CDC calculation, such as hash functions and timestamps |
| Date Column (optional) | Column in the dataset with latest update timestamp for the record in the source system. When left blank, file modified date or ingestion timestamp is used. |
Full Refresh:
A Simple truncate/reload pattern. Used on small datasets where it’s often simpler and more efficient to reprocess the entire dataset vs. identifying what changed and processing incrementally. It keeps a history of previous batches and allows restoring prior versions of data.
Full Refresh Processing steps
- Create new partition in the hub table
- Copy batch data into new partition
- Update hub view definition to mark the partition as current
None Refresh:
Simple append pattern. May be used when source data has already been deduplicated or it is desirable to have full history of changes. Each subsequent batch of data is appended to the dataset.
None Refresh Processing steps
- Create new partition in the hub table
- Copy batch data into new partition
Timestamp Refresh:
Frequently used for time series and transactional data that follows these pattern:
- Does not have natural primary key
- Has non-null date or datetime column representing action or transaction timestamp
- Each batch includes a continuous range of records by transaction timestamp. Each batch may have different ranges, from several minutes to several days, month or more. When ranges overlap in batches, the latest received batch replaces data within its range
Timestamp Refresh Processing steps
- Store configured timestamp column value in new system s_timestamp attribute
- Calculate and store MIN and MAX s_timestamp values for the batch
- Add batch data to the main dataset by replacing overlapping timestamp range, and appending non-overlapping range record, as illustrated below:
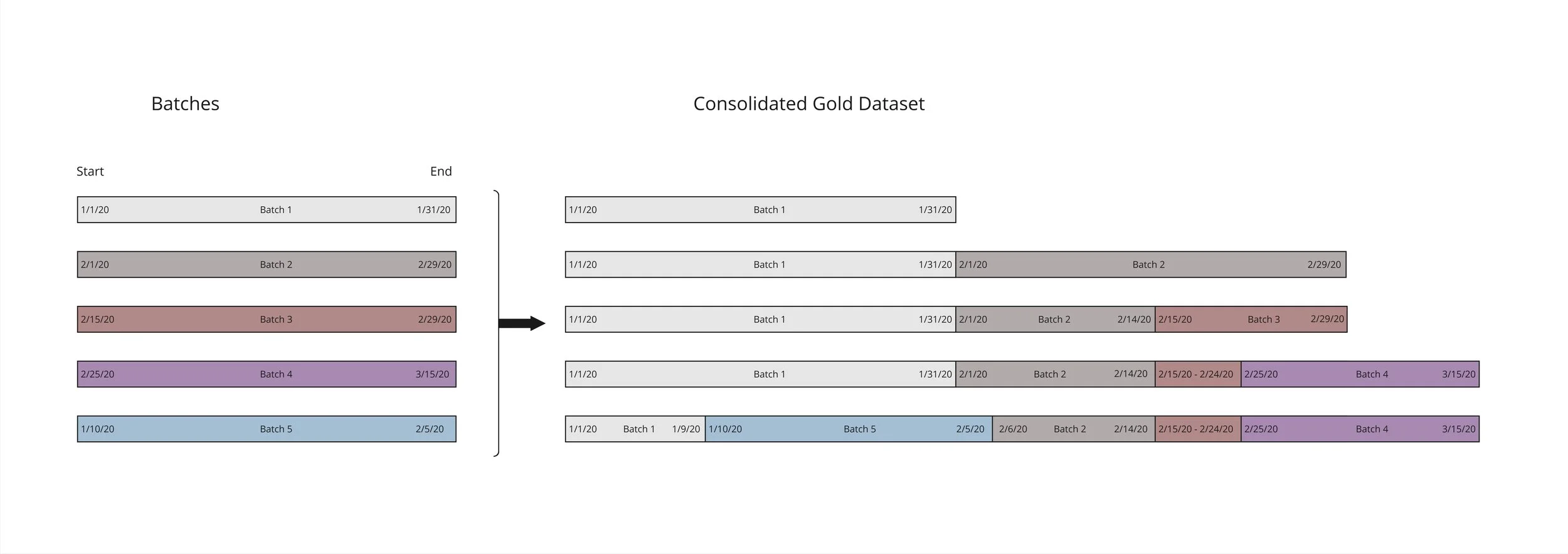
| Parameter | Description |
|---|---|
| Timestamp Column | Transaction timestamp column |
| Datetime Format (optional) | Custom datetime format string |
Sequence Refresh:
Sequence is identical to Timestamp refresh, except that timestamp column is replaced with incrementing numeric sequence attribute.
Custom Refresh:
This pattern allows us to handle more complex data refresh scenarios that don’t fit into 5 categories described above.
Custom Refresh Processing steps
- Evaluate Delete Query and delete hub table records satisfying the criteria
- Append latest batch of data to hub table, optionally pre-filtering it using Append Filter
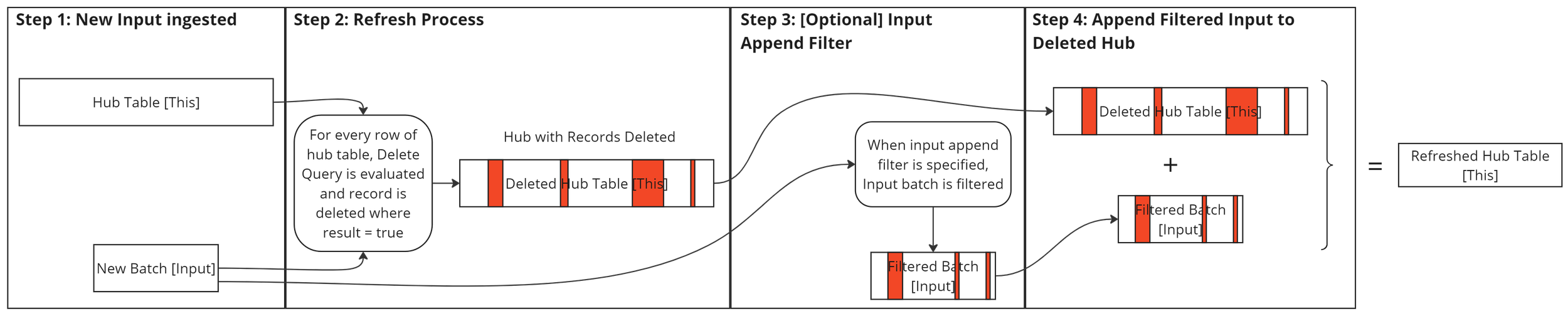
| Parameter | Description |
|---|---|
| Delete Query | Row-pure, boolean-typed expression that defines old records that should be removed from the dataset. It may use 2 aliases: [This] - references the hub table, aka main dataset or Gold table [Input] - references last received batch of data |
| Append Filter (optional) | Row-pure, boolean-typed expression that defines filter (or WHERE clause) for the latest received batch. When specified, it applies filter to the records in the latest batch before appending them to the main dataset |
Secondary Subsystems of Refresh in DataForge
Capture Historic Data
These DataForge refresh types provide means for exposing historic changes to a dataset over time:
| Type | Description |
|---|---|
| Key | History data is automatically captured in the hub_history table. It has a schema identical to the main hub table, but is structured as Type 2 slowly changing dimension, containing multiple copies of each record, one for each change occurrence. In contrast, the main hub table for the key refresh dataset is structured as SCD Type 1 and contains unique rows with latest data. |
| Full | History data is automatically captured in the hub_history table. Each batch of data is added as a new partition to the table. |
| Custom | Custom refresh uses Databricks Delta table storage that has time-travel functionality enabling historic queries. |
| None | History is implicitly contained in the hub table: each partition represents received batch of data. |
| Timestamp, Sequence | The storage location of underlying files is versioned and can be used to roll back to prior version. |
Atomic Processing
This ensures that in case of any processing errors, the main dataset will not get corrupted. It is achieved by 3 complementary mechanisms:
- Separation of refresh processing into 2 distinct phases:
- Capture Data Changes (CDC) phase reads the main data set and current batch, but updates the current batch only. This is typically where most errors occur, caused by bad configuration parameters or bad data in the batch. When this phase fails, the failure has no impact on the main dataset.
- “Refresh” phase updates the main dataset, leveraging system attribute values pre-calculated during the CDC phase. This simplifies the update process as much as possible, minimizing the chance for errors.
Integrated versioning of the main dataset, which enables rolling back to the last stable version of the data when the Refresh phase fails.
Reset All CDC function allows to fully re-process the main dataset from “scratch”, using individual raw batch files stored in the data lake.
Incremental Processing and Source System Querying
When the source dataset contains an accurate timestamp or sequence column that represents the last insert/update datetime for each record, a watermark column parameter can be configured to enable incremental ingestion and processing. Specifying this optional parameter enables use of special reserved tokens in source query that filter data using the last timestamp or sequence value observed in the watermark column. An example of source query using the watermark token:
SELECT * FROM Orders WHERE modified_date >= <latest_timestamp>During ingestion, the value of *<latest_timestamp>*****token is evaluated as MAX(
Reprocessing
Developers often start with the Full refresh pattern - it is the most simple to configure and best suited for initial development while still exploring and discovering dataset characteristics. Later in the development cycle, a developer can update the refresh pattern and associated parameters. After the change, the system will display a confirmation prompt and initialize a reprocessing of the dataset using the new configuration.
Unload and Reload
Mistakes happen, and wrong data batches get loaded into the dataset. It is possible to delete any batch from any DataForge source with a simple click of a button. This is enabled by DataForge’s metadata repository that stores relevant information about every received batch of data for every dataset. The “Delete” process removes one or more selected inputs (batches), updating the dataset to the same state as if deleted batches were never loaded.
Once invalid batches are deleted, the corrected data can be reloaded, even if more recent datasets were loaded into the table. This feature saves a lot of time and stress to developers and support engineers responsible for monitoring platform data feeds.
Observability Metrics
The DataForge Meta Database captures extensive observability metrics for every dataset, batch, and processing step. Here are a few of the many metrics captured and exposed via the DataForge UI that are specific to the Refresh process. Many of these metrics apply to all refresh types, but some are type-specific.
| Metric | Description |
|---|---|
| Record Count | Number of records in the batch |
| Effective Record Count | Number of records from the current batch that still exist in the main dataset or have not been replaced by data from newer batches |
| Record counts by Status Code | These metrics are specific to key refresh. They capture count of records for each record status code, for the batch and full dataset, at the time of batch processing. |
| Effective Ranges | These metrics are specific to timestamp and sequence refresh. They capture effective ranges for each batch, and corresponding record count. |
Conclusion
The Data Refresh process is critical in managing and updating datasets within a data pipeline, consolidating individual batches, or event streams to provide a unified, up-to-date representation of data. Its primary purpose is to eliminate duplicates, capture the latest changes, and maintain data consistency for users. Key features include capturing change history, performing atomic updates, supporting incremental processing, and enabling reprocessing or corrections after configuration changes or errors.
DataForge supports various refresh types tailored for different dataset structures and update needs, from Key-based refresh (leveraging primary keys and timestamps) to simple full reloads, time-series (timestamp or sequence-based) refresh, and even custom criteria-based refreshes. These patterns allow DataForge users to manage data across diverse scenarios with simple configurations, whether the source has natural keys or not.
Lastly, the DataForge Refresh process type includes mechanisms for capturing historical changes, ensuring atomic processing, and offering observability metrics. These features not only safeguard data integrity during updates but also enable easy troubleshooting and performance optimization by exposing key metrics like record counts and effective data ranges.
Stop building your refresh processes by hand and start declaratively defining your pipelines today with a DataForge 30 day free trial.
Ready to try DataForge?
Start with the Community plan — free forever — or talk to our team.