June 20, 2024
Introducing Event Data Processing Using Kafka in DataForge Cloud 8.0
DataForge Cloud 8.0 now enables event integration to do batch writes and reads from any Kafka topic.
Integrate Event Data using Kafka into your workspace

DataForge Cloud 8.0 now enables event integration to do batch writes and reads from any Kafka topic. Data is read directly from the topic in batches and then decoded to String or Struct fields using Avro or JSON schemas to help decode Event stream messages. Schema Registry is supported for platforms that implement it, such as Confluent. For output, data is encoded using Avro or JSON schemas, with Schema Registry also being supported for encoding messages.
In this update, we’ve simplified the process of connecting to a Kafka server and pulling from a Kafka topic or writing to a Kafka topic with our Connection features for extending sensitive and standard JDBC connection parameters. This means users can now connect more efficiently and securely, reducing the complexity and potential errors in the setup process. Users can also reuse the connection to a Kafka server to pull various topics hosted within, rather than defining or storing connection information for every custom notebook written to pull from Kafka in Databricks. This significantly streamlines the workflow, saving time and reducing redundancy, which enhances productivity and minimizes the risk of configuration mistakes.
Offset information is stored on each ingestion, enabling incremental pulls from a topic without the need to manage offset starting and ending points, which can be a pain point for creating a reusable notebook in Databricks that doesn’t pull the entire stream every time. This feature ensures more efficient data processing by only pulling new data, preventing unnecessary data reprocessing, and reducing computational load, which is particularly beneficial for maintaining optimal performance and resource management in Databricks.
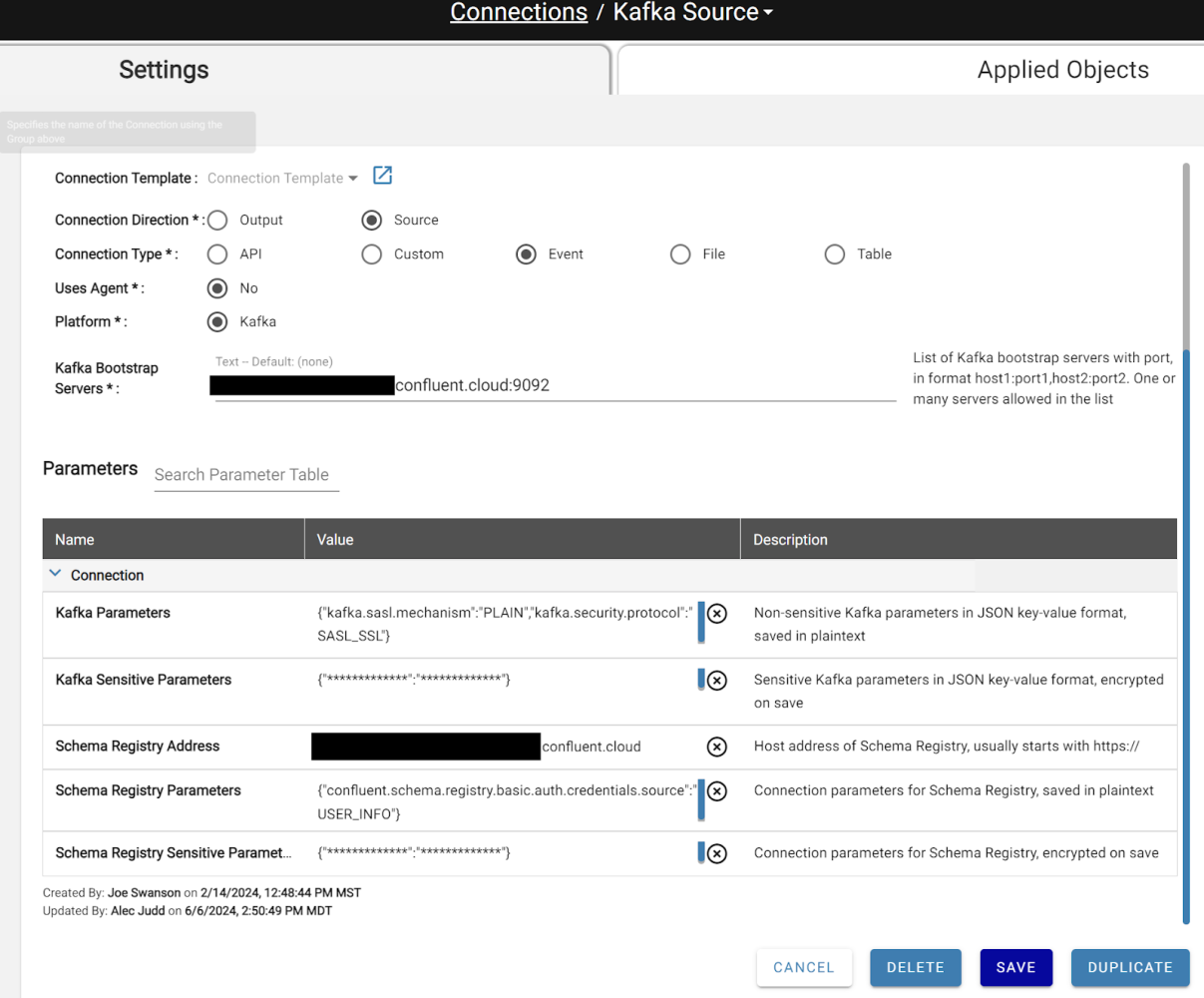
Currently, only batch processing is available; however, the new connector works natively with the existing scheduling services, allowing incremental processing every 15 minutes. Ingestion supports defining starting and ending offsets, with the ability to set the starting offsets to “deltas” to ensure each ingestion always pulls the latest batch from the Kafka topic. Additional parameters exist within the Source ingestion parameters for further refining the data flow.

Key/value columns are supported for output, with the mapping of String and Struct fields being allowed in the key and value. To create a Struct field in DataForge Cloud, a rule must be created on the Source to build the struct using the rule expression “struct([col] as col1, [col] as col2…)”. This rule-based approach ensures consistent and accurate struct creation, reducing manual errors and streamlining the data preparation process.
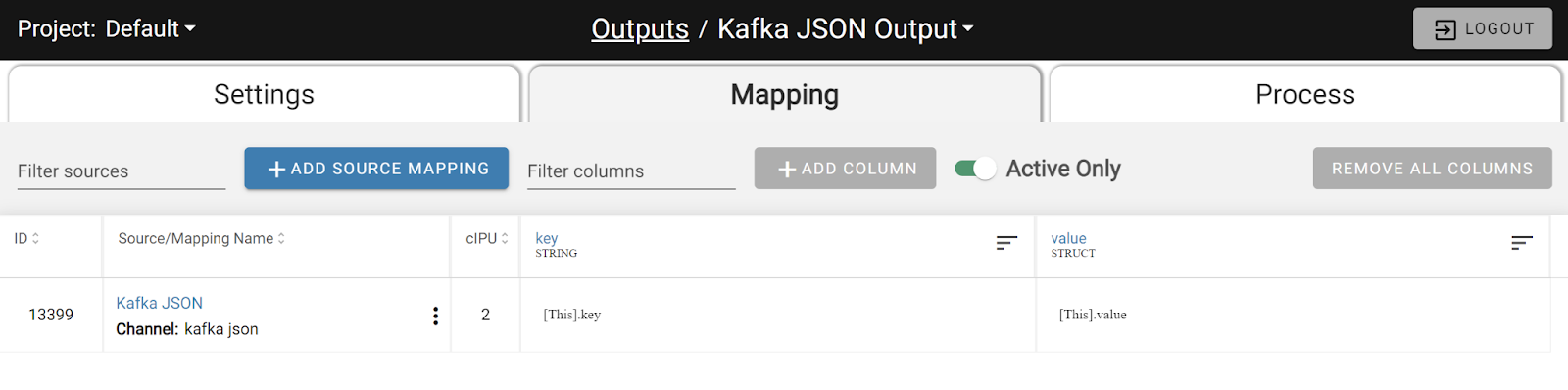
Using the Output schema encoding for JSON or Avro and structuring Output mapping to write key-value pairs directly from DataForge greatly simplifies the notebook code needed to format data for Kafka writes. This simplification of notebook code not only reduces development time and complexity but also enhances the maintainability and scalability of data pipelines, allowing for quicker iterations and easier debugging.
Future Enhancements
- Full streaming integration for ingestion and output
- Support for schema definition in JSON Schema format
These enhancements will enable more use cases and integrations for data sources in DataForge Cloud.
Ready to try DataForge?
Start with the Community plan — free forever — or talk to our team.