August 13, 2024
Introduction to the DataForge Object Model
Part 2 of the DataForge blog series explores the implementation of the DataForge Core framework.
Part 1 of this blog series introduced a new generalized framework for working with SQL transformations by using column-pure and row-pure functions and the associated benefits for regression testing, impact analysis, and extensibility if implemented carefully.
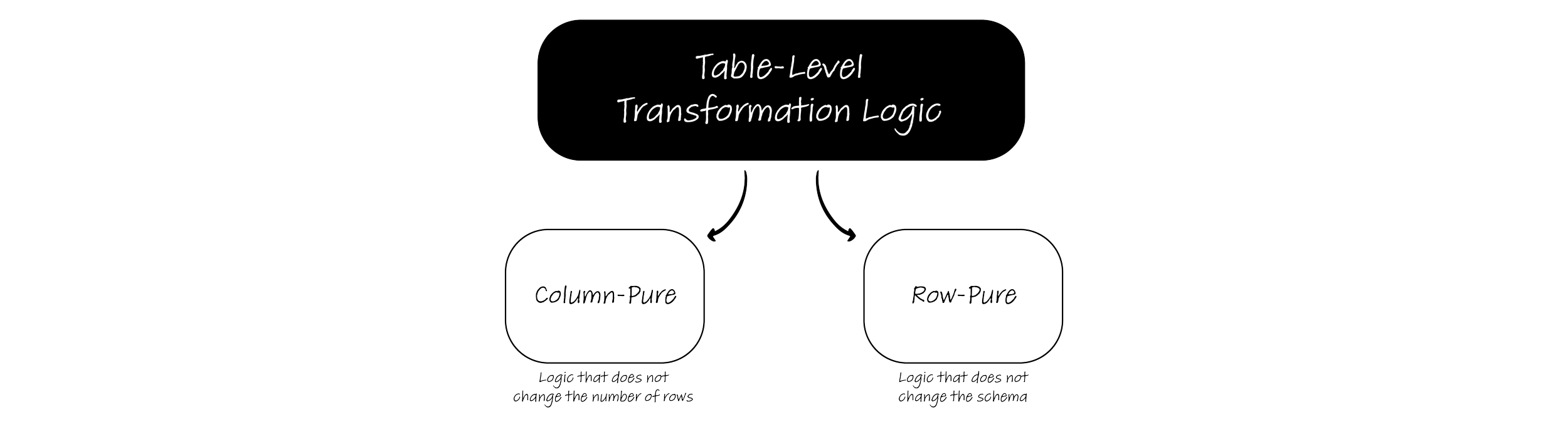
This blog will detail how the team at DataForge implemented these concepts and created a new way for engineers to quickly build and extend data platforms. At the heart of everything is DataForge Core - the open-source implementation of the column and row-pure transformation framework. DataForge Core focuses on taking raw data already landed into the Warehouse/Lakehouse and transforming it into the appropriate target structure(s) by applying the pure transformations in two distinct steps - one for column-pure functions and one for row-pure functions.
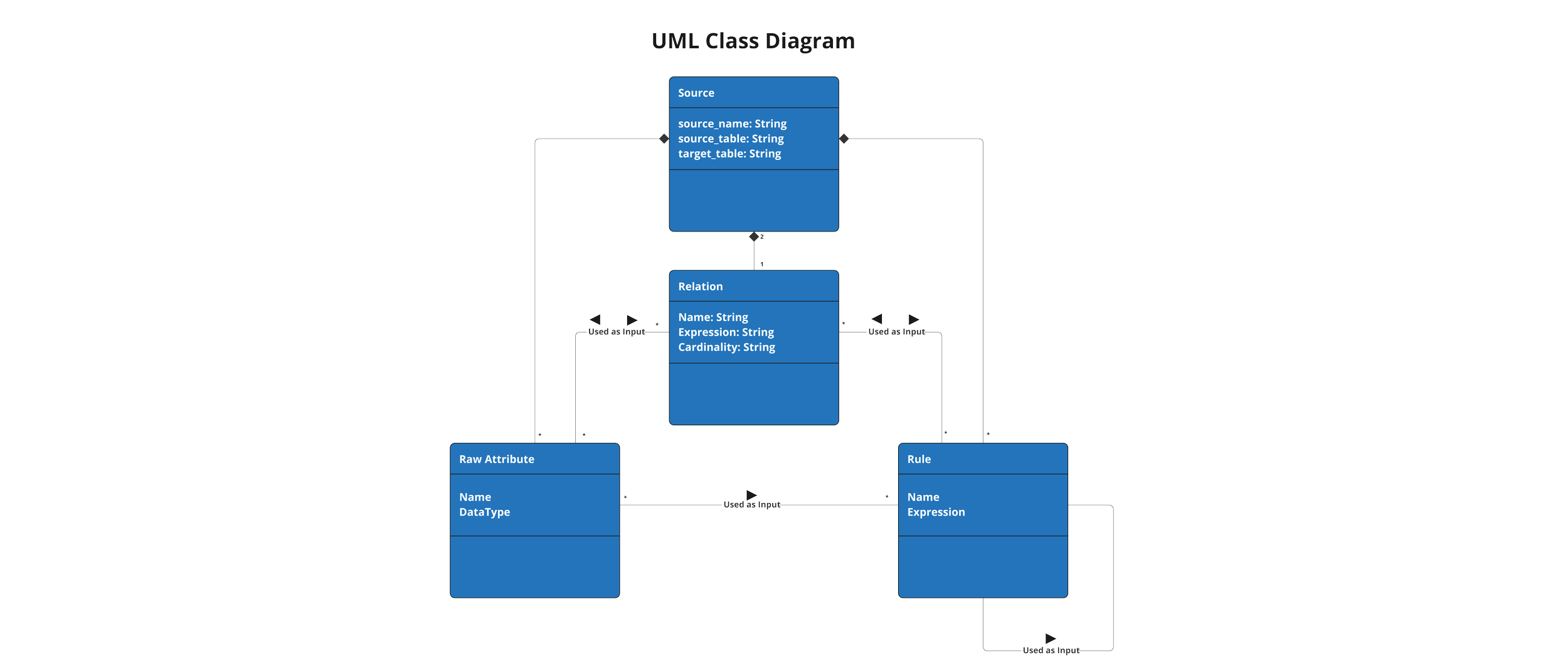
Because the DataForge framework works at a more granular level than tables and SQL statements, new logical objects and code constructs are required to help developers work declaratively and provide compile-time checks to ensure purity of functions within each stage, referential integrity, etc.
This blog will introduce these new logical objects, their analogous structures in computer science, and how using them further promotes software engineering best practices previously unavailable or challenging for data engineers to adhere to.
The DataForge Core Object Model
While the concepts and the associated advantages of the DataForge framework are technology agnostic, it quickly becomes cumbersome to develop and enforce this separation of logic and concerns with vanilla SQL statements, Spark, or dbt - as they require large amounts of boilerplate, duplicative code, and have no built-in structures to protect against accidental mixing of column and row functions.
To solve these issues and improve the developer experience, the new logical objects must balance a few key tenants:
- Limit or eliminate code duplication
- Each type of transform logic should have only one associated object type
Create as few new Class Types and instantiated objects as possible (less is more!)
Rules: Column-Pure SQL Expressions
Starting at the most atomic and fundamental level of the DataForge framework, a Rule is a Class Type representing column-pure functions that define data transformations using SQL expression syntax. They take a set of columns as inputs and produce a single column as an output. These Rules can be chained together to produce a wide variety of transformations and calculations.
Here is an example of a Rule using the DataForge yaml syntax:
rules:
- name: net_price_int
expression: "([This].l_extendedprice - [This].l_tax - [This].l_discount)*100"This function subtracts l_tax and l_discount from l_extendedprice and multiplies the result by 100. But what is [This] and where do l_extendedprice, l_tax, and l_discount come from?
Raw Attributes: External Columns
To differentiate data generated by external systems from transformation results, incoming data columns are given a separate class type: Raw Attributes. From a computer science perspective, these can be thought of as immutable input variables and they act as the starting point for all transformation logic.
In DataForge Core, Raw Attributes must be specified in the codebase to ensure compile time type safety and referential integrity - something only available at runtime in other SQL-based frameworks.
Here is an example of a few Raw attributes in the DataForge yaml syntax:
raw_attributes:
- l_comment string
- l_commitdate date
- l_discount decimal
- l_extendedprice decimal
- l_tax decimal
- l_returnflag boolean
- l_orderkey long
- l_partkey long
- l_suppkey longEach Raw Attribute is independent and has both a name and type, allowing for developers to think of them more as variables to be used in downstream functions, rather than in the context of a table for set-based logic.


Rules can use both Raw Attributes and other Rules as inputs for their expressions.
Source: The Column-Pure Parent Object/Class
Despite the desire to think functionally and operate at only the column level, columns ultimately live within tables/schema. In addition, there are numerous other bits of metadata and structures that may operate at the table level besides just the schema and physical table definition.
Because the new class type in question will hold Raw Attributes which act as the starting point for all other logic, it is given the name of “Source”.
A DataForge Source is a class of objects that hold Raw Attributes, Rules, and other attributes that define the context of the dataset being operated on.
Returning to the earlier example of a Rule, the DataForge syntax includes a lightweight SQL aliasing to help developers quickly specify which Source contains the column (Rule or Raw Attribute) they are referencing in the formula.
rules:
- name: net_price_int
expression: "([This].l_extendedprice - [This].l_tax - [This].l_discount)*100"[This] allows developers to reference Raw Attributes or Rules contained within the same Source as the Rule being defined.
In DataForge Core, a Source has three top level properties:
- source_name: A globally unique name for the instantiated class
- source_table: What table the Raw Attributes come from
- target_table: Where to save the resulting table that contains all Raw Attributes and all Rules
In the DataForge Framework, every Source gets its own file to help with code organization.
Here is a simple example of a Source file:
# tpch_lineitem.yaml
---
source_name: "tpch_lineitem"
source_table: "samples.tpch.lineitem"
target_table: "enriched_lineitem"
raw_attributes:
- l_comment string
- l_commitdate date
- l_discount decimal
- l_extendedprice decimal
- l_tax decimal
- l_returnflag boolean
- l_orderkey long
- l_partkey long
- l_suppkey long
- l_linenumber int
rules:
- name: "rule_net_price_int"
expression: "([This].l_extendedprice - [This].l_tax - [This].l_discount)*100"
- name: "rule_net_price_no_returns"
expression: "CASE WHEN [This].l_returnflag IS TRUE THEN [This].rule_net_price_int ELSE 0 END"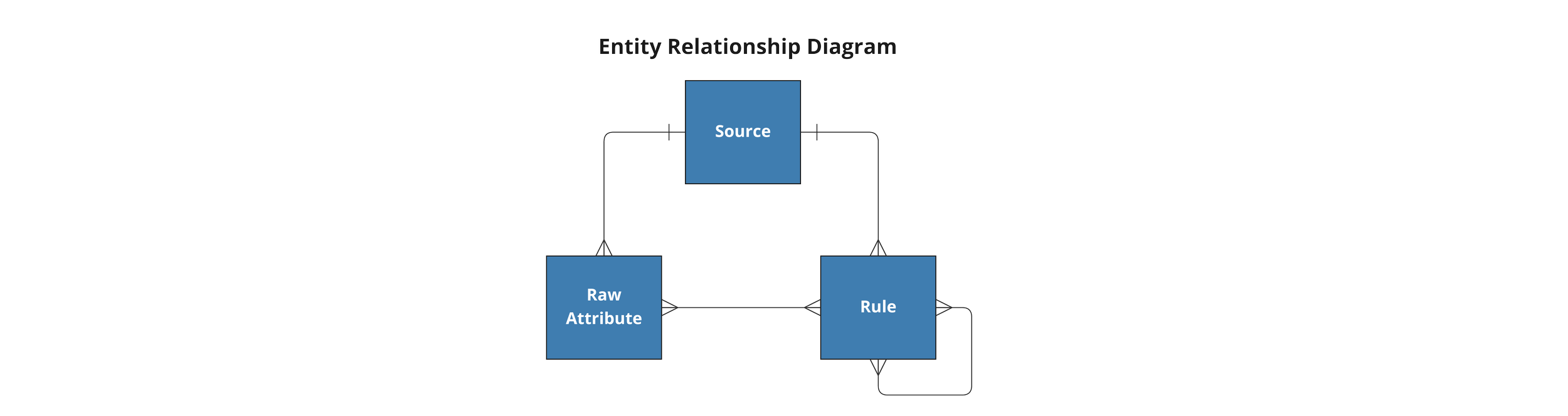
With these three classes developers can write chains of Rules to create new calculated columns to cleanse and enrich the Raw Attributes. While working with Raw Attributes functionally with Rules is powerful, most data transformations include columns from multiple Source Tables. To support this, a new class type is needed to represent the connections between tables.
Relation: JOINs with cardinality
One critical weakness of SQL statements and other frameworks is the embedding of JOIN conditions into the table-level syntax. This almost guarantees code duplication as developers must copy-paste JOIN conditions between tables that are referenced multiple times across different transformations and complex calculations. Even worse, there is no guidance or best practices on how to manage and update changes or tweaks to the source data model. A change to a foreign key constraint in an incoming set of tables can potentially result in a refactoring and reprocessing the majority of the transformation logic.To promote DRY code, DataForge Relations are defined and managed separately from both columnar and row-pure transformation code. By decoupling the connections between Sources from the underlying transformation code, developers can now build, manage, update, and reuse JOINs between tables.
Even better - chains of Relations between multiple Sources create a meta-model at the transformation layer that is separate from both the source system model and the target dataset model(s). This creates an explicit and clear separation of concerns between external systems, transformation, and target data models.
In other frameworks, this transformation data model is scattered among scripts, embedded in the code, and often not supported by the physical tables supporting the transformation code - making it impossible to understand and manage.
In DataForge Core, relations are stored in a dedicated file and contain three components:
- Name: Globally unique name with Source Names included on either side
- Expression: SQL JOIN ON condition detailing the logical connection
- Cardinality: Many to Many, Many to One, or One to One specified in the order of the two Sources in the Name
Here is an example of 3 different relations in DataForge Core syntax:
# relations.yaml
---
- name: "[tpch_lineitem]- orderkey -[tpch_orders]"
expression: "[This].l_orderkey = [Related].o_orderkey"
cardinality: "M-1"
- name: "[tpch_orders]- custkey -[tpch_customer]"
expression: "[This].o_custkey = [Related].c_custkey"
cardinality: "M-1"
- name: "[tpch_lineitem]- partsupp_pkey -[tpch_partsupp]"
expression: "[This].rule_partsupp_pkey = [Related].rule_ps_pkey"
cardinality: "M-1"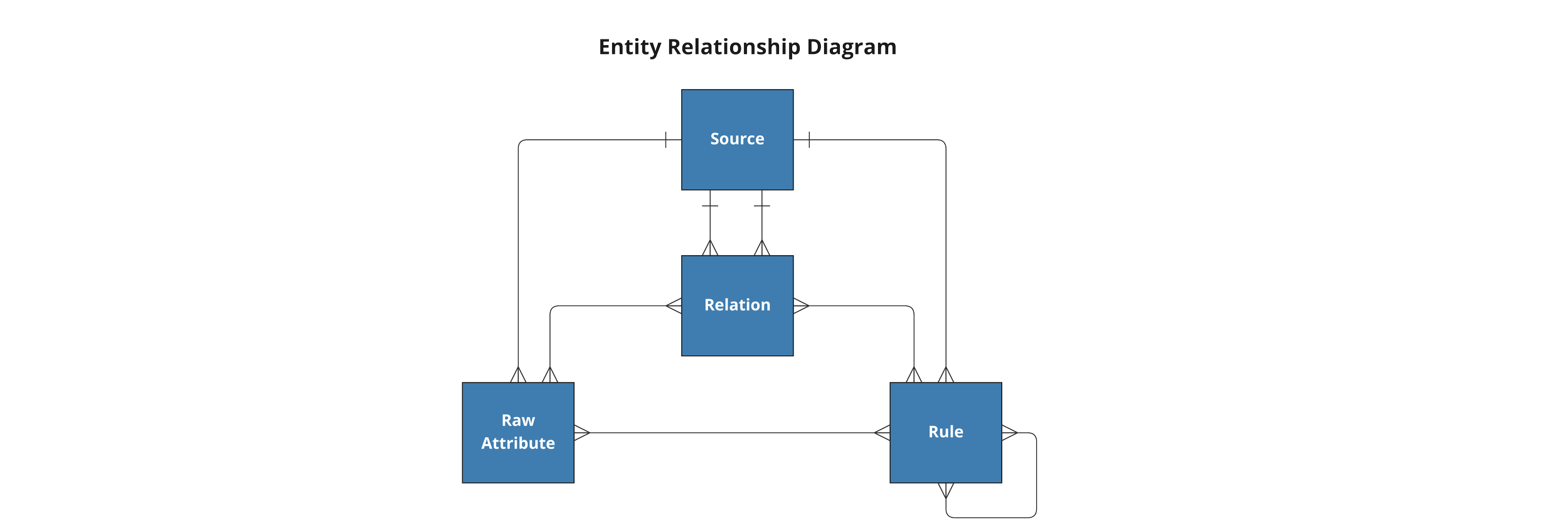
The relations.yaml references the previous tpch_lineitem source example above in addition to three additional Sources: tpch_orders, tpch_customer, and tpch_partsupp.
Here are example files for these three new Sources:
# tpch_orders.yaml
---
source_name: "tpch_orders"
source_table: "samples.tpch.orders"
target_table: "enriched_orders"
raw_attributes:
- o_custkey long
- o_orderdate date
- o_orderkey long
- o_orderstatus string
- o_totalprice decimal# tpch_customer.yaml
---
source_name: "tpch_customer"
source_table: "samples.tpch.customer"
target_table: "enriched_customer"
raw_attributes:
- c_acctbal decimal
- c_address string
- c_custkey long
- c_mktsegment string
- c_name string# tpch_partsupp.yaml
---
source_name: "tpch_partsupp"
source_table: "samples.tpch.partsupp"
target_table: "enriched_partsupp"
raw_attributes:
- ps_availqty int
- ps_partkey long
- ps_suppkey long
- ps_supplycost decimal
rules:
- name: "rule_ps_pkey"
expression: "CONCAT([This].ps_partkey,'|',[This].ps_suppkey)"These files together with the tpch_lineitem.yaml example above create the combined transformation model:
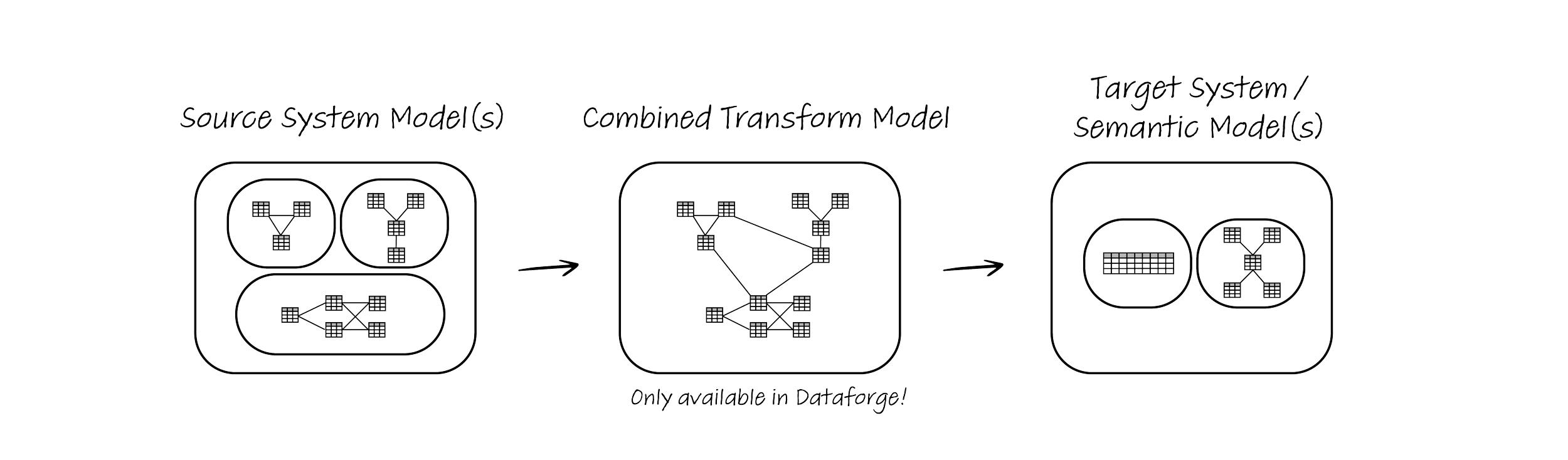
Some important notes:
- The transformation model includes both Raw Attributes and Rules
- Relations can be defined with one or more Raw Attributes and/or Rules
- The Relations often reflect the source system model and augment or extend it with enhanced calculations or combinations of quality checks and cross-table calculations
- An example of a Rule being used in a relation is [tpch_lineitem]- partsupp_pkey -[tpch_partsupp] where the JOIN ON statement uses two Rule expressions to define the Relation rather than Raw Attributes.
The transformation model is global across all target datasets and can easily be incrementally extended with additional column-pure functions and relations - further promoting DRY principles.
In DataForge, this transformation model and the associated persisted tables are also known as theHub.

Traversal: Using Relations to retrieve data across Sources
In the examples above, the Rules only used Rules and Raw Attributes available on the Source where the Rule is defined. To retrieve data from other Sources, Relations must be used to traversebetween Sources and reference Raw Attributes or Rules defined in remote Sources.
Because all Rules have a parent Source object, they have a starting point for navigation of the Hub. A Traversal is when moving logically from one Source to another by using a Relation. Traversals do not have their own object or class, but are distinct from Relations as they have a procedural direction of movement. Relations are defined declaratively and can be traversed in either direction.
Cardinality is critical to include as part of Relation definitions to enforce column-purity of rules - as the number of rows in the resulting dataset from a JOIN between two tables is determined by the cardinality and the direction of the traversal.
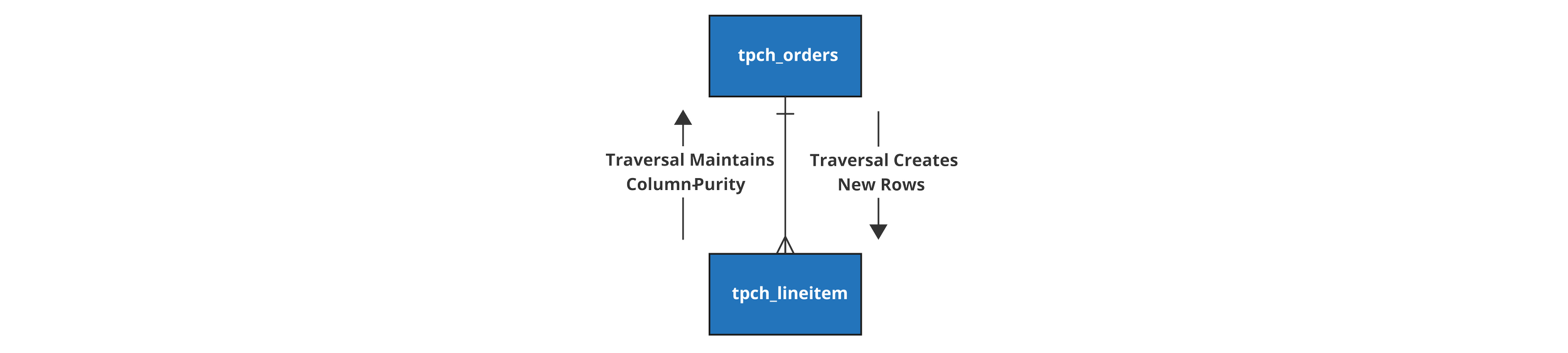
When traversing a cardinality of many-to-one or one-to-one, the number of rows is unchanged - meaning any Rule that uses the Relation in that direction maintains column-purity. When traversing across a one-to-many or a Many-to-Many cardinality, the Rule must include a pre-aggregation statement on the many side to avoid data duplication or the rule will fail at compile time as Rules must be column-pure.
Without any pre-aggregation, traversals must be many-to-one or one-to-one to maintain column-purity. They can be chained together indefinitely so long as they continue to move from many-to-one or one-to-one.
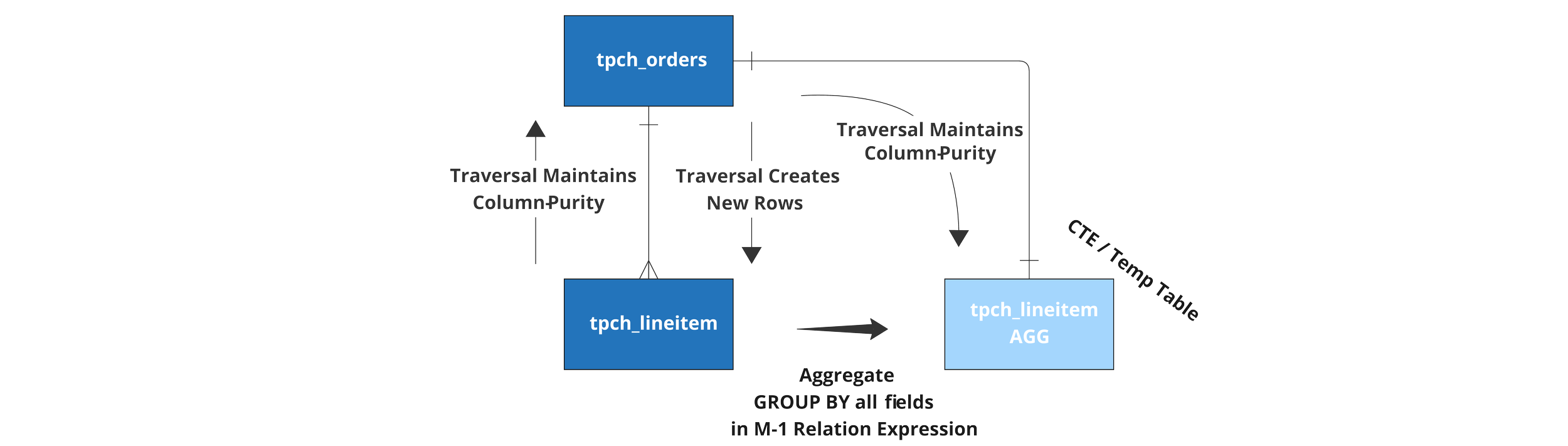
When moving down grain (from many-to-one) in order to maintain column-purity, a pre-transformation must be defined to change the many-to-one relation into a one-to-one. The most common way to do this is by simply grouping by the ID(s) used in the one-to-many JOIN expression. In other words, performing a “rollup” calculation from the lower grain table to the higher. There are other ways to create this new one-to-one relation, but due to the common nature of rollups, this group-by-id pattern is baked into the DataForge Rules syntax and compiler.
Here is an example of a rule using a lookup from tpch_lineitem to orders:
# tpch_lineitem.yaml (excerpt)
...
rules:
...
- name: "rule_discount_ratio"
expression: "[tpch_orders].o_totalprice / [This].l_discount"To reference a Raw Attribute or Rule from another Source that is traversable via many-to-one relations from the current Source, the simple aliasing syntax of [<Source_Name>] can be used rather than [This]. When there are multiple traversal paths between the current Source and the Source that contains the Raw Attribute or Rule, an extended syntax is required. For an example, see this Rule in the sample project included with DataForge Core on Github.
Here is an example of a rule performing the rollup pattern discussed above:
# tpch_orders.yaml (excerpt)
...
rules:
...
- name: "rule_total_price_less_tax"
expression: "[This].o_totalprice - SUM([tpch_lineitem].l_tax)"When referencing a Source field that includes a one-to-many traversal, DataForge requires the reference to be wrapped in an aggregate function to perform the “rollup” operation. If the reference is not wrapped in an aggregate function, the rule will fail to compile.
A few final notes about Relations, Traversals, and Rules:
- Multiple Relations can be defined between two Sources with different cardinalities
- A Source can have a self-referencing Relation (parent/child hierarchy for example)
- Rules and Relations are infinitely composable with each other
- Smaller (less complex logic) Rules and Relations are preferable and best practice when possible
- Small rules promote code reuse across multiple different use cases
Multi-Source circular references will cause compile-time failure in DataForge Core
- Solutions for these patterns are available in DataForge Cloud, but are outside the scope of this blog
Visual representation of a data flow using the Class Types discussed so far:
For contrast, here is a visual example of using dbt models or other frameworks to perform similar transformations:
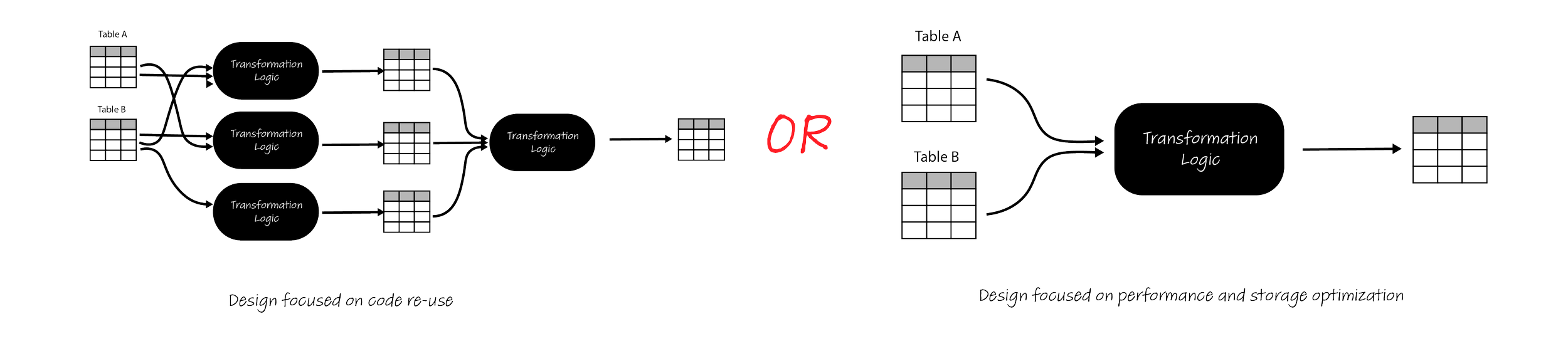
Some key differences between the two approaches:
-
In DataForge, there is exactly one target table for every incoming table
-
In dbt or Spark, an infinite number of models/scripts can be created with associated target tables
-
When to create a new model vs. augment an existing one?
-
In DataForge, target tables contain all columns from original table plus Rules, allowing for easy use and re-use downstream without the need to update the transformation code
-
In dbt or Spark, it is at the developer’s discretion to pass through columns and sometimes impossible due to lack of column-purity, resulting in potential refactoring or regression issues with new changes or additions of columns
-
Each model is a “black-box” of logic, with JOINs and other logic embedded into the model and difficult or impossible to share across models
-
Some code snippets can be shared with Jinja templates and macros, but quickly become clunky to manage at scale
-
Due to black-box nature, column-level lineage becomes a complex calculation and requires separate tooling to visualize and understand logical dependencies
Output Columns: Target table definition(s)
Now that all column-pure transformations are completed, the next step is to perform any required row-pure transformations and save the final results to a target table.
Output Columns are aliases and datatypes of a target table. These act as the Data Definition Language (DDL) for target tables, allowing developers to control target table schemas within the DataForge framework.
In DataForge syntax, Output Columns follow a very SQL-like pattern similar to Raw Attributes:
...
columns:
- "Order Name" string
- "Order Date" date
- "Revenue Less Tax" decimal(18,2)
...Column Map (Mapping): Final aliasing and new-grain aggregates
With the final target columns defined by Output Columns, the next Class Type to explore are Mappings.
In their basic form, Mappings connect Raw Attributes and Rules to Output Columns. They define where the data for a target Output Column comes from within the Hub. Said differently, they are a column-pure aliasing operation with no other calculations. Whereas Rules allow for any Column-pure transformation, Mappings only allow for aliasing.
This extra layer of column-pure aliasing is provided in the DataForge framework to allow developers to define a lightweight semantic layer with different column names from the ones used in Raw Attributes, Rules, and Relations. Column names convenient to use in the transformation layer(s) are often different from the final metrics and dimensional attributes used by business analysts and data scientists. Additionally, the same data can often have different required target names depending on the department, target end users, or API endpoint.
Here are a few basic mappings in DataForge syntax, with the Rule or Raw Attribute listed first and the Output Column second:
...
mappings:
- o_name "Order Name"
- o_orderdate "Order Date"
- rule_total_price_less_tax "Revenue Less Tax"
...Aggregate Mappings behave similarly to a SQL Group By statement, but have the aggregate flag set as the operation_type and include at least one mapping which has an aggregate function applied. All columns that are not wrapped in an aggregate session are implicitly included in the “group by” statement.
...
operation_type: “Aggregate”
mappings:
- o_name “Order Name”
- o_orderdate “Order Date”
- sum(rule_total_price_less_tax) “Revenue Less Tax”
...Important note:
Aggregates in Mappings should only be used when the grain of data does not exist naturally in another Source upstream. If the same operation can be performed within the column-pure Source layer via Rules and Relations, it should be. Rules/Relations are preferred for extensibility and code reuse when compared to Mappings.
Channel: What Source to get the data from
In the previous examples, we provided target columns and mappings, but failed to provide any syntax or instructions to let the framework know what Source in the Hub to look for the Raw Attributes and Rules as the input for the mappings.
A Channel points the Mappings to a Source that holds the Raw Attributes and Rules.
...
channels:
- source_name: tpch_orders
operation_type: "Aggregate"
mappings:
- o_name "Order Name"
- o_orderdate "Order Date"
- sum(rule_total_price_less_tax) "Revenue Less Tax"
...With the Source_name specified, any Raw Attributes or Rules can be used in the Mappings to populate the target Output Columns.
Filter: Row-pure, pre-aggregate WHERE clause
Arguably the most used row-pure transformation, the Filter class type follows the same patterns as a SQL WHERE expression. Any boolean expression using any column from the Source specified in the Channel (including those not in any Mappings!) can be used to reduce the number of rows feeding into the aggregation mappings or target table.
The syntax in DataForge is simple and easy to understand if familiar with SQL WHERE expressions:
...
channels:
- source_name: tpch_orders
filter: "[This].o_orderstatus == 'P'"
operation_type: "Aggregate"
mappings:
- o_name "Order Name"
- o_orderdate "Order Date"
- sum(rule_total_price_less_tax) "Revenue Less Tax"
...Despite their importance, Filters are relatively simple, and thus can be handled as a property on the Channel class rather than their own dedicated Class/Object.
Output: The (mostly) Row-pure parent Object/Class
An Output acts similarly to a Source as a container for all of the Row-pure functions as well as the semantic layer provided by the mapping aliasing. Combining Output Columns, Channels, Filters, and Mappings, Outputs define the target table DataForge produces.
Bringing the full syntax together and adding a name for the target table:
# revenue_by_order_date.yaml
output_name: revenue_by_order_date
columns:
- "Order Name" string
- "Order Date" date
- "Revenue Less Tax" decimal(18,2)
channels:
- source_name: tpch_orders
filter: "[This].o_orderstatus == 'P'"
operation_type: "Aggregate"
mappings:
- o_name "Order Name"
- o_orderdate "Order Date"
- sum(rule_total_price_less_tax) "Revenue Less Tax"Similarly to the Source, an Output holds all of the individual, broken-down components that make up row-pure functions, and their associated references to upstream columns from a Source.
The only missing row-pure operation is the UNION. This fits cleanly into the Output syntax by simply adding an additional Channel with associated mappings.
Here is an example of unioning two sources together:
# reporting.yaml
output_name: reporting
columns:
- "Part Supplier Key" string
- "Part Key" string
- "Supplier Key" string
- "Revenue No Returns" decimal(18,2)
- "Supplier Cost" decimal(18,2)
channels:
- source_name: tpch_lineitem
mappings:
- rule_partsupp_pkey "Part Supplier Key"
- l_partkey "Part Key"
- l_suppkey "Supplier Key"
- rule_net_price_no_returns "Revenue No Returns"
- source_name: tpch_partsupp
mappings:
- rule_ps_pkey "Part Supplier Key"
- ps_partkey "Part Key"
- ps_suppkey "Supplier Key"
- ps_supplycost "Supplier Cost"By specifying two different channels in the Output, DataForge stacks the two channels together via UNION. For convenience, not all columns must be specified in the mappings. Any missing mappings will be NULL for all rows produced in the Output Columns by that Channel.
With this final piece of the puzzle, DataForge has provided exactly one place for every type of relational algebra or metadata - with the only exception being column-pure alias operations available in both Rules and Mappings.
The Full Framework:
Although there are eight new Class Types introduced in the DataForge framework, the intent is to organize structures that already exist within data engineering and SQL relational algebra - not create brand new syntax or logic for transforming data. By breaking down the Spark Dataframe, dbt model, or SQL stored procedure to this more granular, organized, and structured framework, the foundation has been set to develop following computer science principles and best practices, as discussed in Part 1.
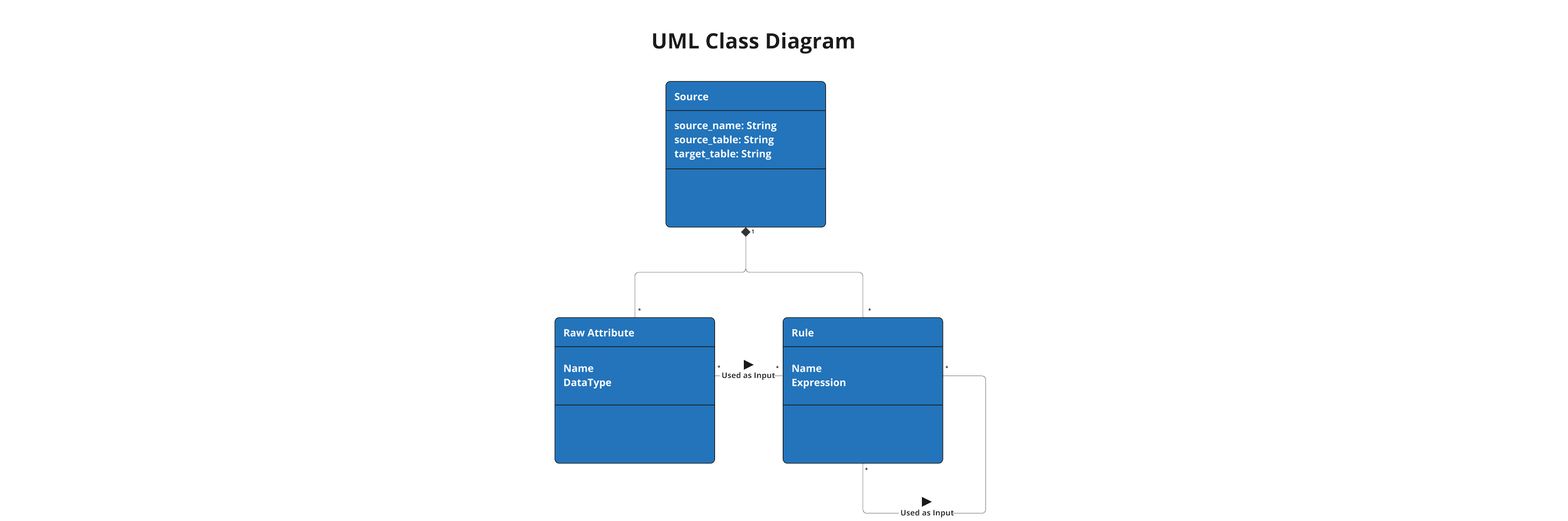
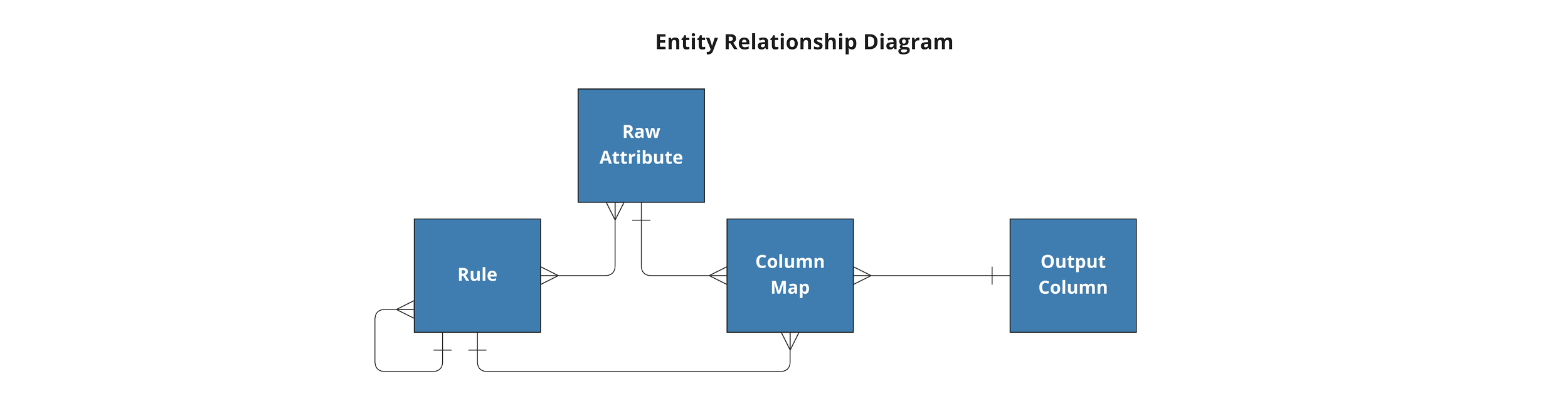
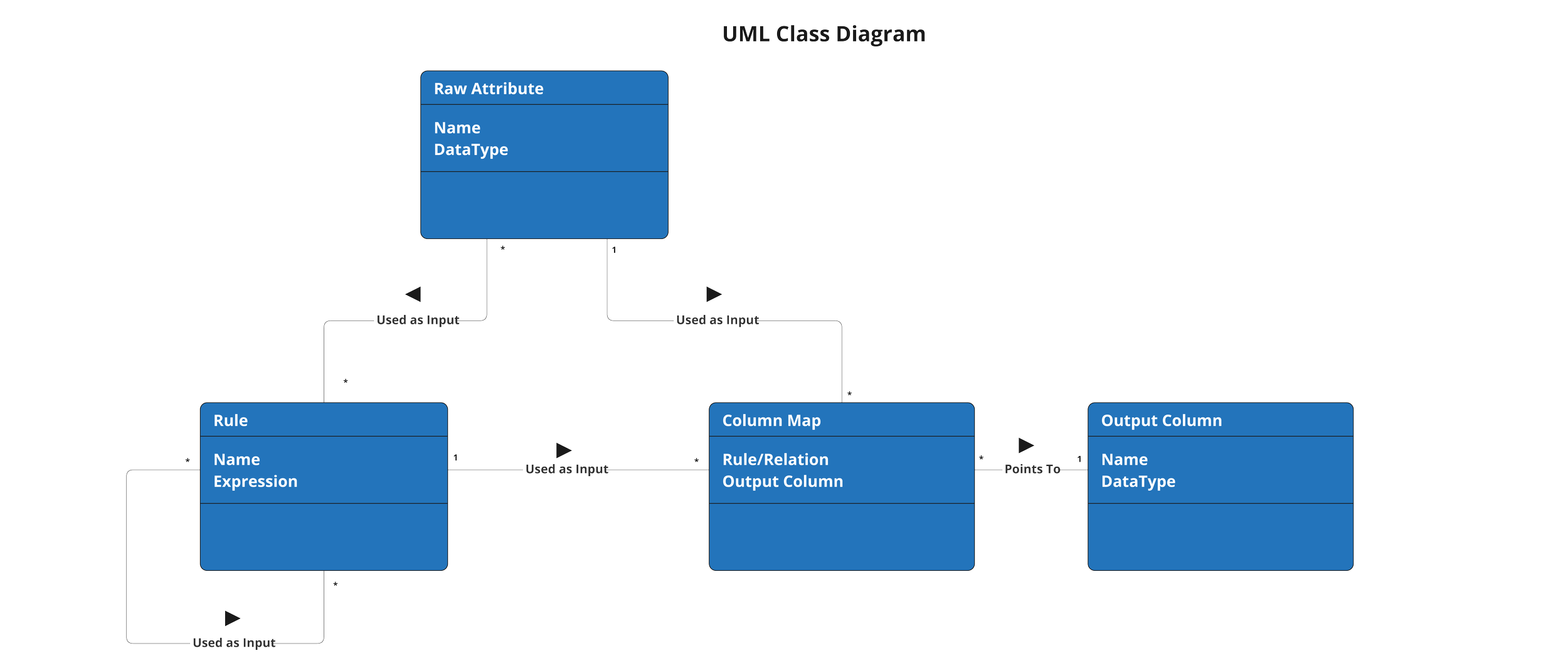
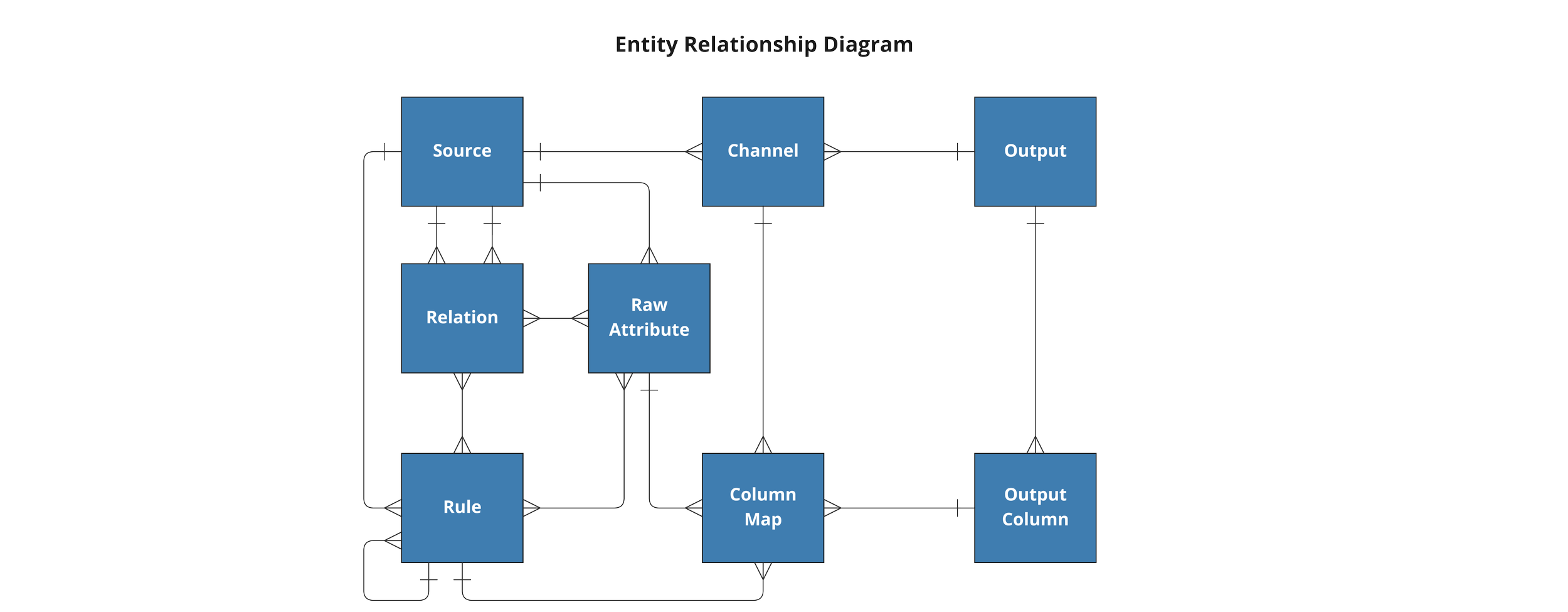
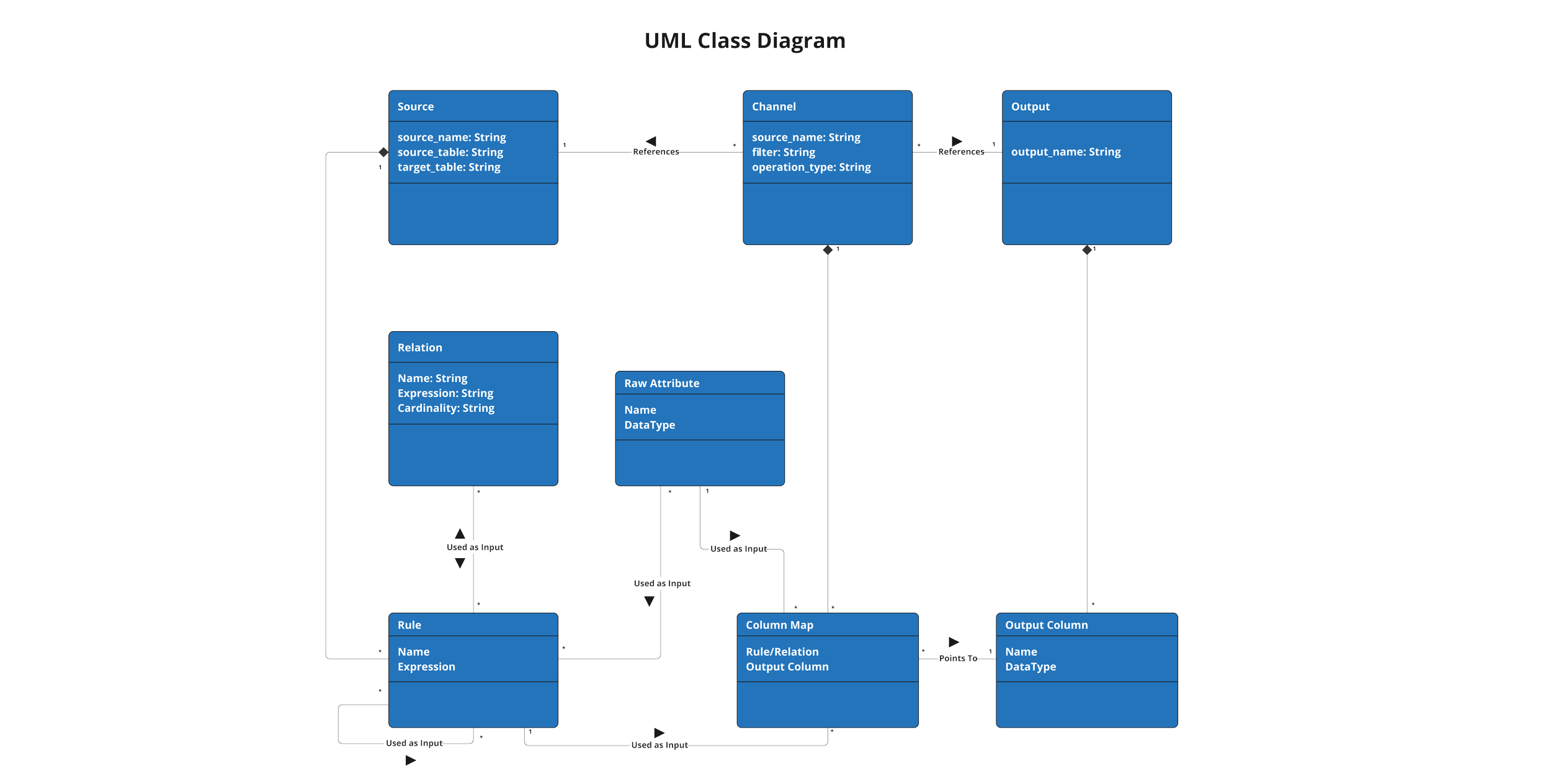
The DataForge framework is also meant to be easy to understand and work with, no matter if your background is in data engineering or software development. The reason both the ERD and UML visuals are provided is because DataForge is simultaneously both a database schema and a class structure.
When developing in DataForge Core using the YAML syntax, developers can engage with the framework in the Class structure to make things such as inheritance and dependencies easy to work with and manage.
If you dig into the codebase for DataForge Core, however, it becomes clear that the framework is a database-first architecture built primarily in PostgreSQL functions that has matching physical tables for every Class type discussed in this blog.
In the process of compiling the codebase (dataforge build command), all Class objects are stored in tables that are easy to query, analyze, and build custom reports on. This means that with a large codebase of 1,000s of Sources and millions of Rules can be easily searched with the most powerful and flexible tool for any data professional: SQL.
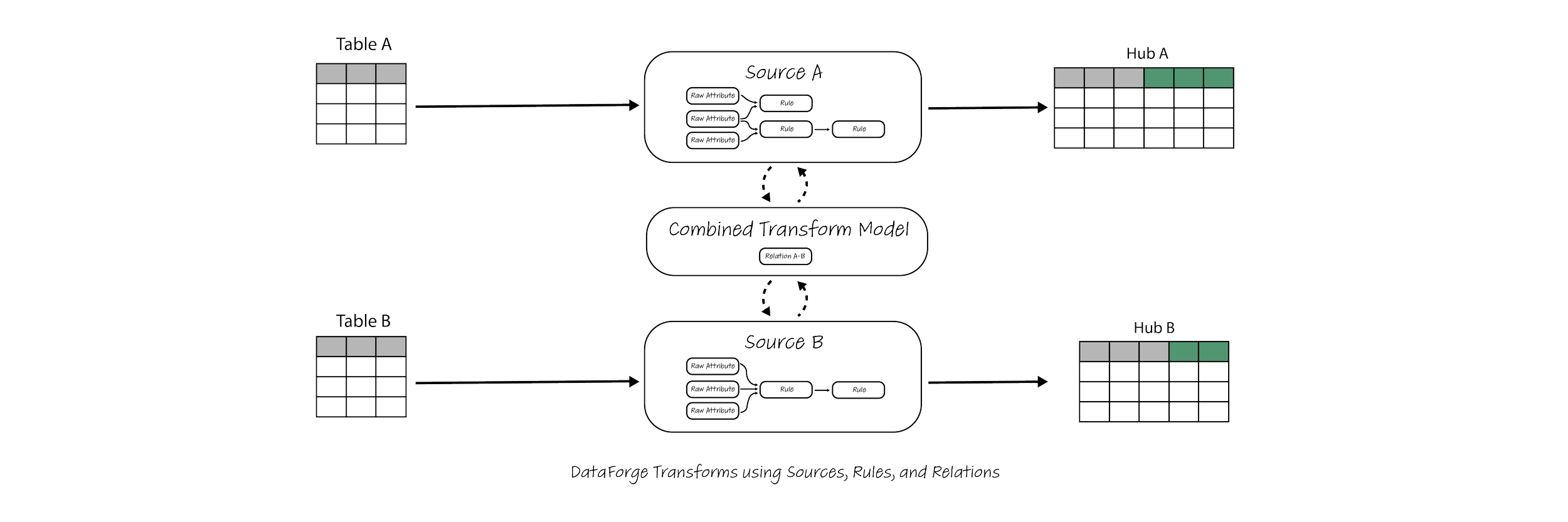
Here is a combined view covering both Sources and Outputs of the dataflow for all tables processed by DataForge:
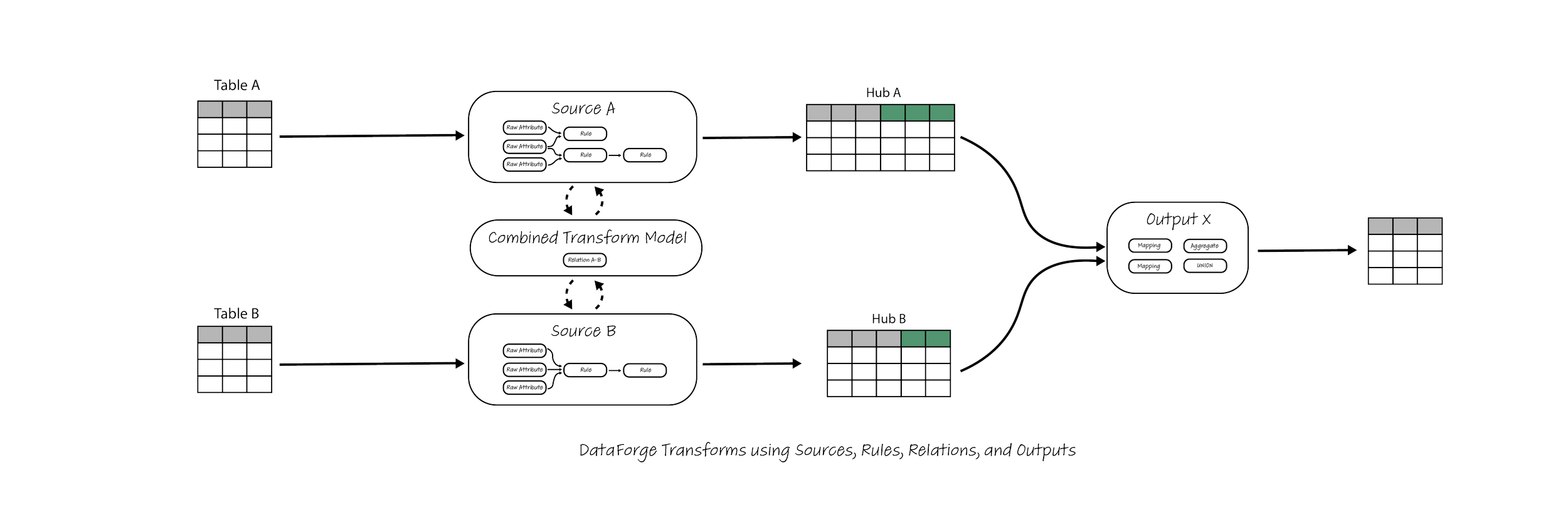
All Sources create a dedicated Hub table, even if no Rules are defined, allowing for easy extensions in the future. Outputs can use as many Sources as needed, and can also branch off a Source multiple times. This means that the same Rules can be reused across multiple target use cases and datasets, encouraging developers to simply branch off the existing Combined Transformation Model and Rules rather than build a parallel and largely duplicative pipeline for their own needs.
A few final notes about DataForge not mentioned in the sections above:
- Sources and Outputs have a many-to-many relationship via channels
- Any source can have an unlimited number of Output definitions and an Output can have an unlimited number of Channels (UNIONs) powering it.
- If adding new row-pure logic and target table, it is often as easy as creating a new Output and mapping to existing Raw Attributes and Rules.
DataForge is typesafe at compile time
- This is why all Raw Attributes and Output Columns must be defined with their datatypes in the code.
- DataForge Cloud provides code automation tools to automatically hydrate Raw Attributes from existing tables, external files, etc. as well as handle complex schema evolution scenarios, and more!
Orchestration is automated at compile time
- The DataForge compiler is able to understand how different Raw Attributes, Rules, and Relations are used by each other and can build a DAG to process everything appropriately for both the Hub and Outputs.
- This SQL is saved in the Targets folder in DataForge Core for analysis and tweaking if needed.
- DataForge Core cannot handle a few corner cases such as complex multi-traversal circular logic.
- DataForge Cloud approaches Orchestration automation in a different way than Core. Cloud builds on the Core scheduler with an event-based microservices-style workflow engine which covers infrastructure, storage, incremental loads, and many other considerations - allowing for any type of orchestration to be automated.
At DataForge, our mission is to automate the tedious and simplify the complex. While at first glance, DataForge Core may seem more complex than writing full SQL statements, when working with enterprise-scale codebases it suddenly becomes much more important to have a system and structure to help developers work together and grow the codebase over time than scraping together a quick script.
Combined with code automations and the web-based development environment provided by DataForge Cloud, it has never been easier to build and evolve a world-class data transformation codebase that will allow your organization to focus on the business logic and avoid the traditional pitfalls of spaghetti code that proliferates with imperative scripts and table-based models.
In the next blog in this series, we will cover the standard processing stages and the out-of-the-box, fully automated Medallion Architecture provided by DataForge Cloud.
Ready to try DataForge?
Start with the Community plan — free forever — or talk to our team.