The Data Platform That Comes Built, Not Assembled
Most data platforms are assembled piece by piece, tool by tool, team by team. DataForge ships with the architecture already built and enforced, so your team focuses on using data, not building the infrastructure to move it.
One platform. Complete architecture. Ready from day one.
Trusted by data leaders at companies like:
The Medallion Problem
Three Layers on the Whiteboard.
Fifty in Production.
Every data team eventually hits the same wall. The team grows. The pipeline count grows. But nothing gets easier. Every new use case gets built a little differently by whoever builds it, and changing anything risks breaking something else.
Medallion was supposed to fix this. Bronze, silver, gold. Three clean layers, a shared mental model that every team could build on. It made sense on a whiteboard.
But three named layers always become fifteen real ones. Teams define them differently. Pipelines accumulate staging tables, temp layers, and custom merge logic that lives in code nobody documents. Tools like dbt, Airflow, and Spark generate procedural code within Medallion's rough outline. They don't enforce the architecture. They just make it faster to drift from it.
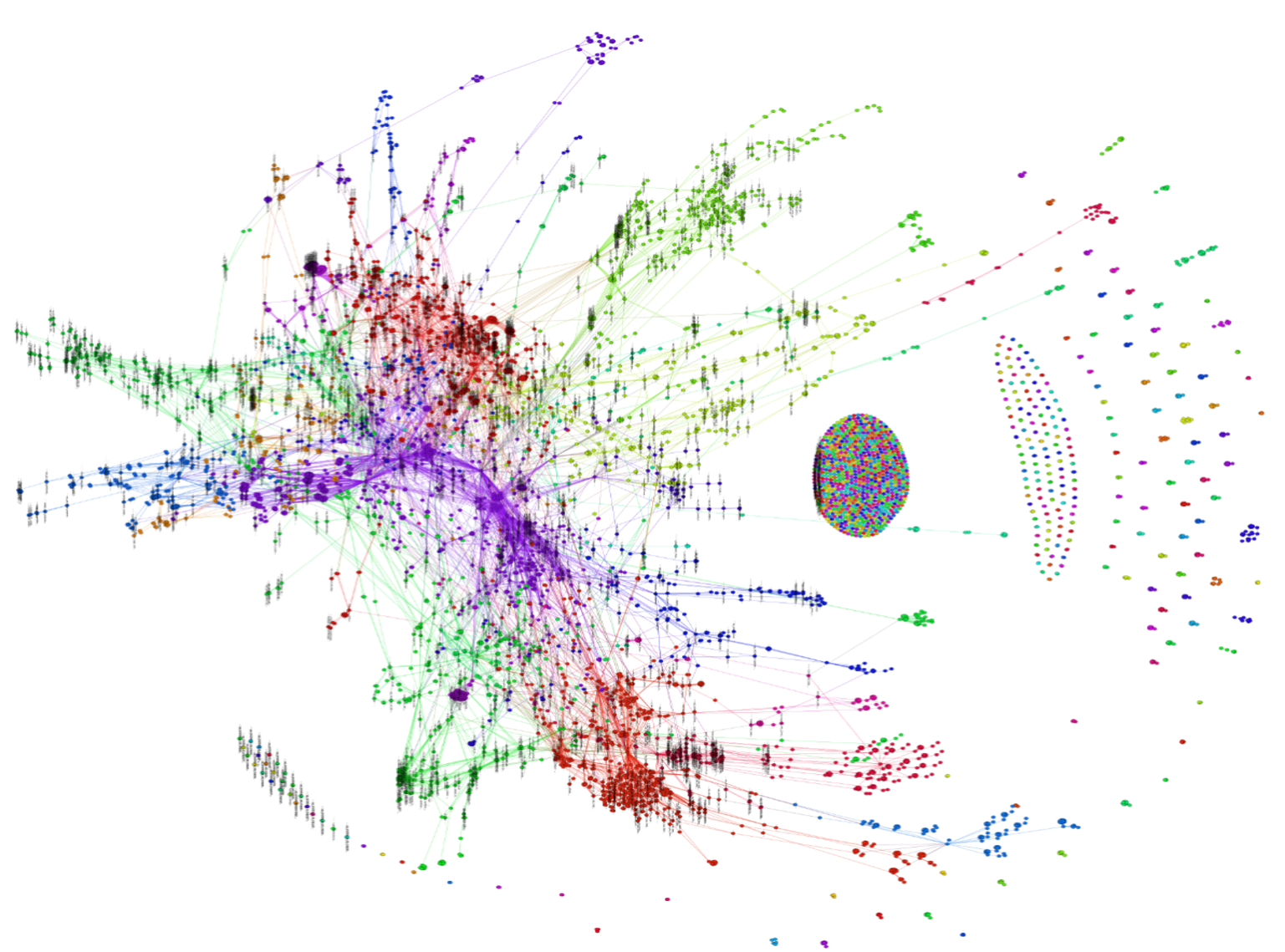
A real Medallion pipeline graph. Not the three layers it was designed to be.
The DataForge Difference
We Built What Medallion Only Promised
DataForge is not another tool to add to your stack. It is the architecture itself, pre-built, opinionated, and enforced. Every pipeline that runs on DataForge follows the same five-stage refinement flow, across every source, every domain, every team. There is no custom interpretation, no manual implementation, no governance to layer on later.
Most tools that call themselves declarative still require you to define every step: every staging layer, every merge, every dependency. That is procedural logic in declarative syntax. DataForge inverts this: you define what the data should look like, and the architecture handles how it gets there. That inversion is only possible when the architecture is fixed. A custom interpretation of a shared idea with hidden procedural layers, like Medallion, makes it impossible.
DataForge enforces how data moves through those stages, not how it's modeled at the output. Dimensional, flat, or operational: your call. Any source. Any target.
The Platform
Three Capabilities. One System.
Alloy, Ember, and Talos are not separate tools. They are the structural, logical, and operational layers of a single platform.
Alloy
The Structured Architecture for Every Pipeline
Alloy defines the foundational architecture that every DataForge pipeline follows. Rather than allowing each new use case to introduce its own design patterns, Alloy enforces a consistent, layered structure for how data is ingested, transformed, and published.
Batch and streaming run through the same architecture. No separate design, no separate layering, no separate operational model. Alloy is not a pipeline builder or orchestration tool. It is the architectural backbone that ensures every pipeline, regardless of source or processing mode, scales cleanly over time.
Learn more
Ember
The Prescriptive Catalog for Pipeline Logic
Ember is the prescriptive catalog that defines how data logic is expressed across the platform. It allows teams to describe column-level transformations and business rules within a shared knowledge graph that reflects how the organization understands its data.
This catalog becomes the system of record for data logic. DataForge translates these definitions into pipelines within Alloy's architecture, while Ember records the results alongside the configurations that produced them. By prescribing how logic is defined at the column level, Ember enables faster iteration and simpler operations as platforms scale.
Learn more
Talos
The AI Control Plane for Data Platforms
Talos is the AI control plane that allows teams to interact with DataForge through natural language. It operates within Alloy's enforced architecture and Ember's prescriptive catalog, using those constraints to guide changes safely and consistently.
Because Talos is grounded in a fixed architecture and defined data logic, it avoids generating speculative or arbitrary logic. Instead, it translates intent into structured updates that conform to the platform's design, reducing the risk of hallucination while accelerating change.
Learn more
Built for the Platforms You Already Use
Native support for Databricks and Snowflake, deployed across AWS, Azure, or Google Cloud.
"Service Logic benefits tremendously from DataForge because it keeps our data integrations organized over time despite a complex and expanding landscape of systems. The platform accelerated our initial data transformation and is easy to maintain and enhance with minimal resources, allowing us to generate clean analytics that demonstrate the value of our business model, all without the need for a large team of in-house data experts."

Levi Reeves
VP of Integrations & FP&A
Ready to build better pipelines?
Join the teams using DataForge to scale their data platforms without the chaos.